▣ 주요 키워드 ▣
- dplyr
- filter, select, arrange, %>%(파이프), mutate, summarise
- rank
- rank옵션, dense_rank, min_rank
⊙ 부서별 최고 급여자들의 정보 출력
1.ddply
a <- ddply(employees,'DEPARTMENT_ID',transform,max_s=max(SALARY)) #각행에 부서별 최고급여를 추출하여 max_s열에 추가
a[a$SALARY == a$max_s,][,-12] # max_s값과 salary갑이 같은 값만 출력
plyr::ddply(employees,'DEPARTMENT_ID',subset,SALARY==max(SALARY)) #subset옵션을 이용하여 간단히 구할 수 있다.
2. aggregate
a <- aggregate(SALARY~DEPARTMENT_ID,employees,max)
merge(a,employees,by=c('DEPARTMENT_ID','SALARY'))
⊙ 부서별로 가장 처음으로 입사한 사원 정보를 출력.
1.ddply
employees$HIRE_DATE <- as.Date(employees$HIRE_DATE,format='%Y-%d-%m')
plyr::ddply(employees,'DEPARTMENT_ID',subset,HIRE_DATE==min(HIRE_DATE))
2.aggregate
a <- aggregate(HIRE_DATE~DEPARTMENT_ID,employees,min)
merge(a,employees,by=c('HIRE_DATE','DEPARTMENT_ID'))
⊙자신의 부서 평균 급여보다 더 많이 받는 사원들의 EMPLOYEE_ID, DEPARTMENT_ID, SALARY를 출력.
1.aggregate
a <- aggregate(SALARY~DEPARTMENT_ID,employees,mean) # 평균급여 들어갈 변수 a
a1 <- merge(a, employees,by='DEPARTMENT_ID')
a1[a1$SALARY.y > a1$SALARY.x,c('EMPLOYEE_ID','DEPARTMENT_ID','SALARY.y')]
dept_avg <- aggregate(SALARY~DEPARTMENT_ID,employees,mean) #평균급여 들어갈 변수 avg
names(dept_avg)[2] <- 'AVG_SAL'
dept_avg
df <- merge(employees,dept_avg)
df[df$SALARY > df$AVG_SAL,c('EMPLOYEE_ID','DEPARTMENT_ID','SALARY','AVG_SAL')]
2.ddply
plyr::ddply(employees,'DEPARTMENT_ID',subset,SALARY > mean(SALARY))[,c('EMPLOYEE_ID','DEPARTMENT_ID','SALARY')]
#ddply를 사용하면 더욱 간단하게 표현할 수 있다.

★ dplyr 패키지 함수 사용하기
▶filter
기존의 필터링
employees[employees$DEPARTMENT_ID == 20,]
subset(employees,DEPARTMENT_ID == 20)
● dplyr 패키지
install.packages("dplyr")
library(dplyr)
●dplyr::filter() : 조건에 해당하는 것을 필터링하는 함수
dplyr::filter(employees,DEPARTMENT_ID==20)
▶select
● dplyr::select() : 특정한 컬럼을 선택하는 함수
dplyr::select(employees,EMPLOYEE_ID,LAST_NAME,SALARY,DEPARTMENT_ID)
dplyr::select(employees,1,4,7) # 1,4,7번 컬럼 추출
dplyr::select(employees,1:7) # 1~7까지 컬럼 추출
dplyr::select(employees,-1,-4,-7) # 1,4,7번 컬럼 빼고 추출
dplyr::select(employees,-LAST_NAME,-FIRST_NAME) # LAST_NAME,-FRIST_NAME을 제외하고 추출
▶ dplyr::arrange : 정렬
기존에 있던 정렬
x <- subset(employees,SALARY>=10000,select=c(LAST_NAME,SALARY)) # salary값이 10000이상인 값들중 last_name,salary컬럼만 x변수에 저장
order(x$SALARY,decreasing = T) # 인덱스로 정렬(내림차순
x[order(x$SALARY),] # 오름차순
x[order(x$SALARY,decreasing=T),] #내림차순
library(doBy) #doBy 패키지의 orderBy함수
doBy::orderBy(~SALARY,x) # 오름차순
doBy::orderBy(~-SALARY,x) # 내림차순
doBy::orderBy(~-SALARY+LAST_NAME,x)# SALARY내림차순정렬, LAST_NAME 오름차순정렬
● dplyr::arrange() : 정렬
arrange(x,SALARY) # 오름차순정령
arrange(x,desc(SALARY)) # 내림차순정령
arrange(x,desc(SALARY),LAST_NAME) # SALARY내림차순정렬, LAST_NAME 오름차순정렬
#sql
select last_name, job_id, salary
from employees
where salary >= 10000
order by salary;


▶%>%(파이프) : 여러 문장을 조합해서 사용하는 방법 연산자.(dplyr에서만 사용)
# 데이터프레임을 선두로 파이프를 계속 연결하면서 조건을 추가할 수 있다. 그리고 위에서부터 코드가 수행되니 주의하자.
employees%>% #데이터프레임
select(LAST_NAME,JOB_ID,SALARY)%>% #조건1 LAST_NAME,JOB_ID,SALARY를 출력
filter(SALARY>=10000)%>% #조건2 SALARY가 10000이상인 것
arrange(desc(SALARY),LAST_NAME) #대상컬럼이 위에 있는 컬럼만 사용가능 없으면 오류 , 조건3 SALARY를 내림차순, LAST_NAME을 오름차순으로 정렬
▶ dplyr::mutate : 새로운 컬럼을 추가하는 함수, 미리 보기
# 컬럼추가
employees$ann_sal <- employees$SALARY * 12
head(employees)
#컬럼 삭제
employees$ann_sal <- NULL
head(employees)
● dplyr::mutate
dplyr::mutate(employees,ann_sal=SALARY*12) # 미리보기
df <- mutate(employees,ann_sal=SALARY*12)
head(df)
⊙30번 부서 사원들이면서 급여는 5000 이상인 사원들의 employee_id, salary, department_id를 출력
(dplyr 패키지에 있는 함수를 이용하세요.)
employees%>%
select(EMPLOYEE_ID,SALARY,DEPARTMENT_ID)%>% #select가 먼저돌아감
filter(DEPARTMENT_ID ==30 & SALARY >= 5000)
employees%>%
filter(DEPARTMENT_ID ==30 & SALARY >= 5000)%>% #filter가 먼저돌아감
select(EMPLOYEE_ID,SALARY,DEPARTMENT_ID)
⊙30번 또는 50번 부서 사원들이면서 급여는 5000이상인 사원들의 employee_id, salary, department_id를 출력하세요.
(dplyr 패키지에 있는 함수를 이용하세요.)
employees%>%
select(EMPLOYEE_ID,SALARY,DEPARTMENT_ID)%>%
filter((DEPARTMENT_ID==30 |DEPARTMENT_ID==50) & SALARY >= 5000)
⊙월요일에 입사한 사원들의 LAST_NAME, SALARY, HIRE_DATE를 출력하세요. 입사한 날짜를 기준으로 오름차순 정렬
(dplyr 패키지에 있는 함수를 이용하세요.)
employees%>%
select(LAST_NAME,SALARY,HIRE_DATE)%>%
filter(format(HIRE_DATE,'%A')=='월요일')%>%
arrange(HIRE_DATE)
library(lubridate)
employees%>%
select(LAST_NAME,SALARY,HIRE_DATE)%>%
filter(wday(HIRE_DATE,week_start=1,label=T)=='월')%>%
arrange(HIRE_DATE)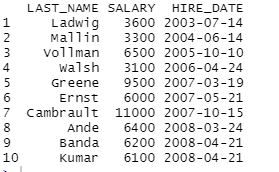
● 전체 집계값
data.frame(sum_sal = sum(employees$SALARY),
mean_sal = mean(employees$SALARY))
plyr::summarise(employees,sum_sal=sum(SALARY),mean_sal=mean(SALARY))
dplyr::summarise(employees,sum_sal=sum(SALARY),mean_sal=mean(SALARY))
employees%>%
dplyr::group_by(DEPARTMENT_ID)%>%
dplyr::summarise(sum_sal=sum(SALARY))
employees%>%
dplyr::group_by(DEPARTMENT_ID)%>%
summarise(sum_sal=sum(SALARY)) # summarise 함수 사용시에 패키지이름을 지정하지 않으면 우선순위는 plyr::summarise가 수행된다.
employees%>%
dplyr::group_by(DEPARTMENT_ID)%>%
plyr::summarise(sum_sal=sum(SALARY)) #원하는 값을 출력하지 못하고 전체집계값만나옴
▶ 로드된 패키지 확인, 해지
# 로드된 패키지 확인
search()
# 로드된 패키지 해지
detach(package:plyr,unload=TRUE)
detach(package:dplyr,unload=TRUE)
search()
▶ summarise_if
employees%>%
dplyr::summarise_if(is.numeric,c(sum,mean),na.rm=T) # 형식이 numeric인 컬럼들의 sum과 mean을 계산하여 컬럼을 만듬, na값은 빼기
employees%>%
dplyr::summarise_if(is.integer,c(sum,mean),na.rm=T)
str(employees)
employees%>%
dplyr::summarise_if(is.character,c(max,min,NROW))
employees%>%
dplyr::summarise_if(is.integer,c(max,min,length))
⊙부서별 급여의 총액을 구한 후 10000 이하 정보만 출력해주세요
(1) tapply
x <-tapply(employees$SALARY,employees$DEPARTMENT_ID,sum) # department_id별로 salary의 합을 구해서 x변수에 넣음 (가로)
x <- data.frame(x) # 데이터프레임 형식으로 바꾸어줌
names(x) <- 'SUM_SAL' # 컬럼 이름 변경
x # 컬럼이 sun_sal밖에없는 것을 확인
rownames(x) # rownames 확인
x$DEPARTMENT_ID <- rownames(x) #새 컬럼에 rownames(x)에 들어간 department_id값을 넣음
x
rownames(x) <- NULL # rownames를 제거
x <- x[,c(2,1)] # 컬럼 위치변경
x[x$SUM_SAL <= 10000,] # sum_sal의 값이 10000이상 값 출력
(2) aggregate
a <-aggregate(SALARY~DEPARTMENT_ID,employees,sum)
a[a$SALARY <= 10000,]
(3) plyr::ddply
x <- plyr::ddply(employees,'DEPARTMENT_ID',summarise,SUM_SAL=sum(SALARY))
na.omit(x[x$SUM_SAL <= 10000,])
(4) dplyr
employees%>%
dplyr::group_by(DEPARTMENT_ID)%>%
dplyr::summarise(SUM_SAL=sum(SALARY))%>%
dplyr::filter(SUM_SAL <= 10000)
⊙부서별, 요일별 입사 인원수를 출력하세요.
(1) tapply
tapply(employees$EMPLOYEE_ID,
list(employees$DEPARTMENT_ID,lubridate::wday(employees$HIRE_DATE,week_start=1,label=T)),length,default=0)
(2) aggregate
1.
aggregate(EMPLOYEE_ID~DEPARTMENT_ID+format(HIRE_DATE,'%A'),employees,NROW)
2.
aggregate(EMPLOYEE_ID~DEPARTMENT_ID+lubridate::wday(employees$HIRE_DATE,week_start=1,label=T),employees,length)
(3) plyr::ddply
df1 <- format(employees$HIRE_DATE,'%A')
df <- employees
df$yoil <- df1
plyr::ddply(df,c('DEPARTMENT_ID','yoil'),summarise,cnt=NROW(EMPLOYEE_ID))
plyr::ddply(employees,c('DEPARTMENT_ID','lubridate::wday(employees$HIRE_DATE,week_start=1,label=T)'),summarise,cnt=length(EMPLOYEE_ID))
(4) dplyr
options(tibble.print_max=Inf) #tibble의 행을 제한하지 않고 모두 출력하게 하는 옵션
options(tibble.print_max=10)
employees%>%
dplyr::group_by(DEPARTMENT_ID,lubridate::wday(employees$HIRE_DATE,week_start=1,label=T))%>%
dplyr::summarise(cnt=length(EMPLOYEE_ID))


★ rank
x <- c(85,80,90,70,60,80,NA)
x
sort(x)
sort(x,decreasing=F, na.last=NA) #오름차순 na값 미포함
sort(x,decreasing=T, na.last=NA) # 내림차순 na값 미포함
sort(x,decreasing=T, na.last=T) # 내림차순 na값 마지막에 포함
sort(x,decreasing=F, na.last=T) # 오름차순 na값 마지막에 포함
sort(x,decreasing=T, na.last=F) # 내림차순 na값 맨 처음에 포함
sort(x,decreasing=F, na.last=F) # 오름차순 na값 맨 처음에 포함
order(x) # 인덱스로 순서
x[order(x)] # 오름차순
x[order(x,decreasing=F,na.last = T)] # 기본값
x[order(x,decreasing=T,na.last = T)] # 내림차순
#오름차순 순위
x <- c(85,80,90,70,60,80,NA)
rank(x)
data.frame(점수 = x,
순위 = rank(x))
data.frame(점수 = x,
순위 = rank(x,na.last = T,ties.method = 'average')) # 기본값, 같은 점수일 경우 평균을 구해서 순위를 나타냄
data.frame(점수 = x,
순위 = rank(x,na.last = T,ties.method = 'first')) # 같은 점수면 앞쪽에 있는 것이 우선
data.frame(점수 = x,
순위 = rank(x,na.last = T,ties.method = 'last')) # 같은 점수면 더 늦게 들어온 값(뒤쪽에 있는 것이) 우선
data.frame(점수 = x,
순위 = rank(x,na.last = T,ties.method = 'random')) # 같은 점수면 랜덤하게 순위를 매겨줌줌
data.frame(점수 = x,
순위 = rank(x,na.last = T,ties.method = 'max')) # 같은 점수면 동차의 최대값으로 통일
data.frame(점수 = x,
순위 = rank(x,na.last = T,ties.method = 'min')) # 같은 점수면 동차의 최소값
data.frame(점수 = x,
순위 = rank(x,na.last = 'keep',ties.method = 'min')) # na값은 일단 na로
data.frame(점수 = na.omit(x),
순위 = rank(x,na.last = NA,ties.method = 'min')) # 행의 수 때문에 na는 제거하고 구하기
data.frame(점수 = x,
순위_1 = rank(x,na.last = T,ties.method = 'min'),
순위_2 = dplyr::min_rank(x), #dplyr패키지의 min_rank도 비슷하게 쓰임
순위_3 = dplyr::dense_rank(x)) # dplyr::dense_rank(x) 연이은 순위 오름차순


- 전부 비교해보면 조금씩 틀리다는 것을 알 수 있다. 직접 해보면서 익히자
# 내림차순 순위
data.frame(점수 = x,
순위_1 = rank(-x,na.last = T,ties.method = 'min'), # '-'표시 내림차순
순위_2 = dplyr::min_rank(desc(x)),
순위_3 = dplyr::dense_rank(desc(x))) # dplyr::dense_rank(desc(x)) 연이은 순위 내림차순
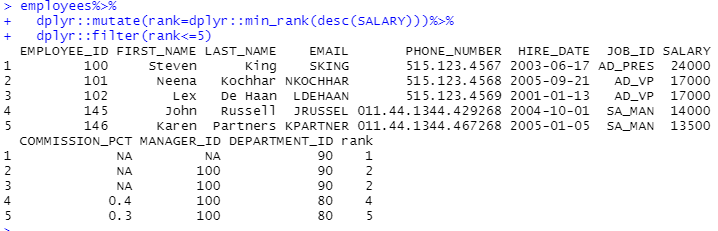
⊙급여를 많이 받는 순으로 순위를 구한 다음에 1등 에서 5위까지 출력해주세요.
연이은 순위를 이용하세요(dense_rank)
1.
employees%>%
dplyr::filter(dplyr::dense_rank(desc(employees$SALARY)) <=5)
employees%>%
dplyr::mutate(rank=dplyr::dense_rank(desc(SALARY)))%>%
dplyr::filter(rank<=5)
employees%>%
dplyr::mutate(rank=dplyr::min_rank(desc(SALARY)))%>%
dplyr::filter(rank<=5)
#min_rank와 dense_rank의 차이는 dense_rank는 연이은 순위로 공동2등이 2명나와도 그다음은 3등이되는데
min_rank는 공동2등이 2명나오면 그 다음은 4등이 된다.
2.
employees$rank <- dplyr::dense_rank(desc(employees$SALARY))
employees[employees$rank <= 5,]
employees$rank <- NULL
head(employee)
⊙ ann_sal 새로운 칼럼을 생성하세요. 값은 commission_pct NA 면 salary * 12,
아니면 (salary * 12) + (salary * 12 * commission_pct) 입력한 후 ann_sal칼럼의 값에 내림차순 기준으로
10위까지 출력
1.
employees$ann_sal <- ifelse(is.na(employees$COMMISSION_PCT),employees$SALARY*12,
(employees$SALARY*12)+(employees$SALARY*12*employees$COMMISSION_PCT))
head(employees)
employees$rank <- dplyr::dense_rank(desc(employees$ann_sal)) #dense_rank
employees[employees$rank <= 10,]
employees$min_rank <- dplyr::min_rank(desc(employees$ann_sal)) #min_rank
employees[employees$rank <= 10,]
employees$ann_sal <- NULL
employees$dense_rank <- NULL
employees$min_rank <- NULL
2.
employees%>%
dplyr::mutate(ann_sal = ifelse(is.na(COMMISSION_PCT),SALARY*12,
(SALARY*12)+(SALARY*12*COMMISSION_PCT)),
dense_rank=dplyr::dense_rank(desc(ann_sal)),
min_rank=dplyr::min_rank(desc(ann_sal)))%>%
dplyr::filter(dense_rank<=10)


'R' 카테고리의 다른 글
| R barplot, 산점도 (0) | 2022.01.25 |
|---|---|
| R dplyr, sqldf함수 (0) | 2022.01.21 |
| R subset,ddply 함수 (0) | 2022.01.19 |
| R merge (0) | 2022.01.17 |
| R 함수(function) (0) | 2022.01.16 |