▣ 주요 키워드 ▣
- subset
- ddply
⊙ locations테이블을 locations.csv 파일로 export 한 후 loc 변수로 로드하세요.
Toronto 지역에 근무하는 사원들의 LAST_NAME,SALARY,DEPARTMENT_ID,DEPARTMENT_NAME,STREET_ADDRESS 정보를 출력
loc <- read.csv('c:/data/locations.csv',header = T) # locations.csv파일 불러와서 loc변수에 저장
# sqldevelope에서 익스포트 받을 때 한 필드에 공백문자나 컴마가 있으면 큰따옴표로 구분해서 익스포트
employees <- read.csv('c:/data/employees.csv',header=T)
departments <- read.csv('c:/data/departments.csv',header = T)
a <- employees[,c('LAST_NAME','SALARY','DEPARTMENT_ID')] # emp데이터프레임에서 last_name,salary,department_id컬럼만 가져와서 a변수에 저장
loc1 <- loc[loc$CITY == 'Toronto',] # 미리 조건을 구하기, loc데이터프레임의 city컬럼에 Toronto와 같은 값을 가지는 데이터의 전체행을 loc1에 변수에 저장
b <- merge(merge(a,departments),loc1)[,c('LAST_NAME','SALARY','DEPARTMENT_ID','DEPARTMENT_NAME','STREET_ADDRESS')]
# merge함수를 2중으로 사용하여 3개의 데이터프레임을 조인하고 출력할 컬럼들만 가져와서 b변수에 저장
b
_______________________________________________________________
z <- merge(loc[loc$CITY == 'Toronto',],departments,by.x='LOCATION_ID',by.y='LOCATION_ID')
#merge(loc[loc$CITY == 'Toronto',],departments,by='LOCATION_ID') #위의 줄이랑 같음
merge(z,employees,by='DEPARTMENT_ID')[,c('LAST_NAME','SALARY','DEPARTMENT_ID','DEPARTMENT_NAME','STREET_ADDRESS')]
⊙아래 화면의 결과처럼 출력해주세요.
부서이름 부서별 급여
Administration 4400
Marketing 19000
Accounting 20308
......
소속부서X 7000
사원 총급여 696456
x <- aggregate(SALARY ~ DEPARTMENT_ID, employees,sum) # 부서id별로 급여의 합계를 구해서 x변수에 저장
y <- merge(x,departments)[,c('DEPARTMENT_NAME','SALARY')] # departments데이터프레임과 x를 조인해서 출력할 컬럼만 뽑아서 y변수에 저장
z <- data.frame(DEPARTMENT_NAME = '소속부서X', #소속 부서가 없는 salary값의 합을 구하는 데이터프레임을 w변수에 저장
SALARY = sum(employees[is.na(employees$DEPARTMENT_ID),'SALARY']))
w <- data.frame(DEPARTMENT_NAME = '사원총급여', # 총급여를 구하는 데이터프레임을 z변수에 저장
SALARY = sum(employees$SALARY))
s <- rbind(y,z,w) #y,z,w변수들을 병합
s
names(s) <- c("부서이름","부서별급여총액") #컬럼명 변경
s
⊙ 부서별 최소 급여를 받고 있는 사원 정보를 출력
dept_min <- aggregate(SALARY ~ DEPARTMENT_ID,employees,min)
merge(dept_min, employees, by=c('DEPARTMENT_ID','SALARY'))
# 컬럼명이 다를 때
dept_min <- aggregate(SALARY~DEPARTMENT_ID,employees,min)
names(dept_min) <- c('dept_id','min_sal')
merge(dept_min,employees,by.x=c('dept_id','min_sal'),by.y=c('DEPARTMENT_ID','SALARY'))#컬럼이름이 다를 때
#sql
select *
from ( select department_id, min(salary) minsal
from employees
group by department_id) e1, employees e2
where e1.department_id = e2.department_id
and e1.minsal = e2.salary;
select *
from employees
where (department_id,salary) in (select department_id, min(salary) minsal
from employees
group by department_id);
★ subset
- 조건에 만족하는 데이터를 선택하는 함수
employees[employees$DEPARTMENT_ID == 20,] #NA값이 나옴
employees[which(employees$DEPARTMENT_ID == 20),] #NA값 안 나옴
subset(employees,DEPARTMENT_ID==20) #NA값 안 나옴
#DEPARTMENT_ID가 20인 사원들의 정보 추출
employees[which(employees$DEPARTMENT_ID == 20),c('LAST_NAME','SALARY')]
subset(employees,DEPARTMENT_ID==20,select = c('LAST_NAME','SALARY'))
subset(employees,DEPARTMENT_ID==20,select = c(LAST_NAME,SALARY))
#subset함수를 사용해서 department_id가 20번이 부서의 사원들의 정보 중 원하는 컬럼을 출력할 때
select 옵션을 사용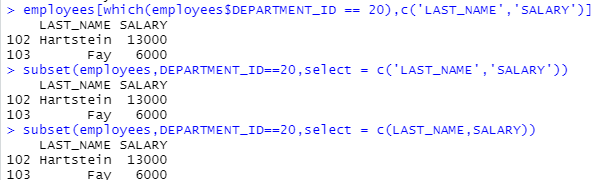
⊙ 30번 부서 사원이면서 급여는 3000이상 받는 사원들의 LAST_NAME, HIRE_DATE, SALARY, DEPARTMENT_ID출력
1. 기존방식
employees[employees$DEPARTMENT_ID==30 & employees$SALARY >= 3000, c('LAST_NAME','HIRE_DATE','SALARY','DEPARTMENT_ID')]
2. subset
subset(employees,DEPARTMENT_ID==30 & SALARY >= 3000, select=c(LAST_NAME,HIRE_DATE,SALARY,DEPARTMENT_ID))
⊙입사한 날짜가 2002,2003년도에 입사한 사원들의 last_name, hire_date, salary, job_id, department_id 출력
subset(employees,format(as.Date(employees$HIRE_DATE,format='%Y-%m-%d'),'%Y') %in% c('2002','2003'),
select=c(LAST_NAME,HIRE_DATE,SALARY,JOB_ID,DEPARTMENT_ID))
# hire_date는 현재 문자형이므로 날짜형으로 변경하고 년도만 출력되게 format함수를 사용했다.
⊙150번 사원의 급여보다 더 많은 급여를 받는 사원들의 last_name, salary를 출력
1. subset함수 사용
a <- subset(employees,EMPLOYEE_ID==150,select = c(LAST_NAME,SALARY))
subset(employees, SALARY> a$SALARY, select = c(LAST_NAME,SALARY))
# 특별한 상황
s <- subset(employees,EMPLOYEE_ID==150,select=SALARY) #data.frame으로 뽑아짐
class(s)
subset(employees,SALARY > s, select=c(LAST_NAME,SALARY)) # 결과값의 오류발생
# subset에서 비교값은 단일값으로 설정해서 비교(데이터프레임 값으로 비교x)
subset(employees,SALARY > as.integer(s), select=c(LAST_NAME,SALARY))
#
2. 기존방식
a <- employees[employees$EMPLOYEE_ID==150,c('LAST_NAME','SALARY')]
employees[employees$SALARY > a$SALARY, c('LAST_NAME','SALARY')]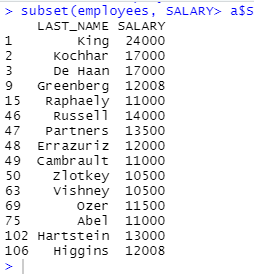
⊙ 부서 이름별 총액, 평균, 최대를 출력. 단 소속부서가 없는 정보도 출력
x1 <- aggregate(SALARY~ifelse(is.na(DEPARTMENT_ID),0,DEPARTMENT_ID),employees,sum)
x2 <- aggregate(SALARY~ifelse(is.na(DEPARTMENT_ID),0,DEPARTMENT_ID),employees,mean)
x3 <- aggregate(SALARY~ifelse(is.na(DEPARTMENT_ID),0,DEPARTMENT_ID),employees,max)
#aggregate함수를 사용하여 각 sum, mean, max함수를 따로 구하고 x1,x2,x3변수에 저장
x1;x2;x3
names(x1) <- c('DEPARTMENT_ID','SUM_SAL')
names(x2) <- c('DEPARTMENT_ID','AVG_SAL')
names(x3) <- c('DEPARTMENT_ID','MAX_SAL')
# 컬럼이름이 너무 길어지고 달라져서 merge를 할 수 없기에 다시 이름을 바꾸어줌
x1;x2;x3
m <- merge(merge(x1,x2),x3) #0(department_id값이 na)는 안나옴
result <- merge(m,departments, all.x=T)[,c('DEPARTMENT_NAME','SUM_SAL','AVG_SAL','MAX_SAL')] # all.x=T옵션으로 안나오던 na값까지 x축 값 모두 출력
result[is.na(result$DEPARTMENT_NAME),'DEPARTMENT_NAME'] <- '소속부서x' # na값이 들어가 있는 자리에 소속부서x라는 값으로 바꾸어줌
result
str(result)
#sql
select department_id, sum(salary), avg(salary),max(salary)
from employees
group by department_id;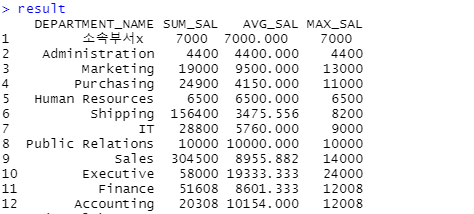
★ ddply
- 데이터 프레임을 분할하고 함수를 적용한 뒤 데이터 프레임으로 결과를 반환하는 함수
# 먼저 ddply함수를 사용하기 위해서는 plyr패키지를 다운받아야 한다.
install.packages("plyr")
library(plyr)
#summarise : 기준컬럼의 데이터끼리(그룹) 모은 후 함수에 적용 sql문의 group by절과 동일하다.
# 위의 문제를 ddply를 사용해서 풀어보면 다음과 같이 간단해진다
x <- plyr::ddply(employees,'DEPARTMENT_ID',summarise, #ddply(데이터프레임, 기준컬럼, summarise,~)
SUM_SAL = sum(SALARY),
AVG_SAL = mean(SALARY),
MAX_SAL = max(SALARY))
x
result <- merge(x,departments,all.x = T)[,c('DEPARTMENT_NAME','SUM_SAL','AVG_SAL','MAX_SAL')]
result[is.na(result$DEPARTMENT_NAME),'DEPARTMENT_NAME'] <- '소속부서x'
result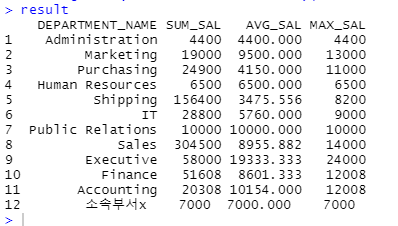
⊙sales.csv file 읽어 들인 후 과일 이름별 판매량(qty), 판매 합계를 구하기.(단 tapply를 이용하세요)

x <- tapply(sales$price,sales$name,sum) # 이름별 판매합
y <- tapply(sales$qty,sales$name,sum) # 이름별 판매개수합
cbind(x,y) # 열 결합
names(x)
df <- data.frame(name=names(x),qty=x,price=y) #데이터프레임으로 만들기
rownames(df) <- NULL #필요없는 행 이름 없애기
df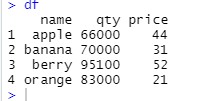
⊙과일 이름별 판매량, 판매합계를 구하세요.(단 aggregate를 이용하세요)
sum_sal <- aggregate(price~name,sales,sum)
cnt_sal <- aggregate(qty~name,sales,sum)
merge(sum_sal, cnt_sal)
⊙과일 이름별 판매량, 판매합계를 구하세요. (단 ddply함수를 이용하세요)
ddply(sales,'name',summarise,
SUM_SAL = sum(price),
CNT_SAL = sum(qty))
⊙연도별로 판매량 중에 가장 많은 판매를 한 년도를 출력해주세요.(단 tapply를 이용하세요)
x <- tapply(sales$qty,sales$year,max)
names(x[x==max(x)]) # 1번 방법
rownames(x)[x==max(x)] #2번 방법
⊙년도별로 판매량 중에 가장 많은 판매를 한 년도를 출력해주세요.(단 aggregate를 이용하세요)
a <- aggregate(qty~year,sales,max)
a[a$qty ==max(a$qty),'year']
⊙년도별 과일 판매 비율을 출력해주세요.( 각 년도에서 과일 판매 비율)
1.
x <- aggregate(qty~year, sales,sum) # 년도별 과일 판매 개수 합 x변수에 저장
x
df <- merge(x,sales,by='year') # x와 sales데이터프레임 병합 year기준으로
df$pct_qty <- df$qty.y/df$qty.x *100 # df데이터프레임에 새로운 컬럼pct_qty에 비율 저장
df[,-2] <- 년도별 과일 판매개수 합 열 빼고 출력
2. for문사용
x <- aggregate(qty~year, sales,sum)
x
z <- NULL
for(i in 1:nrow(sales)){
z <- c(z,sales[i,'qty'] / x[x$year == sales[i,'year'],'qty'] * 100)
}
z
sales$ratio <- z
sales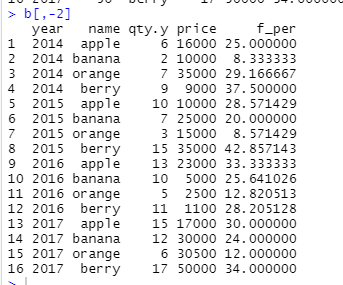
▶ddply의 옵션
-summarise, transform, mutate
#summarise : SQL GROUP BY절 그룹을 수행한 집계값
ddply(sales,'year',summarise,sum_qty=sum(qty))
#transform : 행별로 연산을 수행해서 행당 값을 출력하는 기능 # SQL 분석함수와 유사하다. sum(qty) over(partition by year)
ddply(sales,'year',transform,sum_qty=sum(qty))
ddply(sales,'year',transform,sum_qty=sum(qty), pct_qty=qty/sum(qty)*100)
ddply(sales,'year',transform,sum_qty=sum(qty),pct_qty=qty/sum_qty*100) # 오류발생, 연산결과를 재사용할 수 없다
#mutate : transform기능과 유사하고 차이점은 연산결과를 재사용할 수 있다.
ddply(sales,'year',mutate,sum_qty=sum(qty),pct_qty=qty/sum_qty*100)

⊙연도별로 가장 많이 판매된 정보를 출력해주세요.
1.
df <- ddply(sales,'year',summarise,name=name,qty=qty,price=price,qty_max= qty==max(qty)) #summarise는 컬럼들을 다 적어줘야한다.
df[df$qty_max==TRUE,]
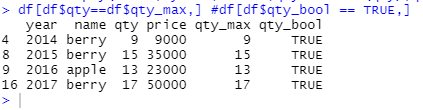
2.
x <- aggregate(qty~year,sales,max)
df <-merge(x,sales,by='year')
df[df$qty.x==df$qty.y,]
3.
df <- ddply(sales,'year',transform,qty_max=max(qty))
df[df$qty==df$qty_max,]
4.
df <- ddply(sales,'year',mutate,qty_max=max(qty),qty_bool= qty==qty_max)
df[df$qty==df$qty_max,] #df[df$qty_bool == TRUE,]
# 컬럼들을 구성하지 않고 true에 해당하는 열만 보고 싶다.
ddply(sales,'year',transform,qty==max(qty)) # truefalse가 안나옴
ddply(sales,'year',summarise,qty==max(qty)) # truefalse만 나옴
ddply(sales,'year',transform,max_bool = qty==max(qty)) #전부 다 나옴
ddply(sales,'year',subset,qty==max(qty)) # 원하는 답이 나옴
#subset : 그룹함수의 결과가 나올 조건을 수행하는 기능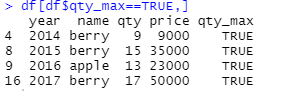


'R' 카테고리의 다른 글
| R dplyr, sqldf함수 (0) | 2022.01.21 |
|---|---|
| R dplyr, rank 함수 (0) | 2022.01.20 |
| R merge (0) | 2022.01.17 |
| R 함수(function) (0) | 2022.01.16 |
| R 조건제어문, 반복문 (0) | 2022.01.13 |