▣오늘의 주요 키워드▣
- 계층검색
- 권한
- 테이블생성
- 유저생성
- DCL
- DML
- TCL
복습 문제
[문제88] pivot을 이용해서 아래 화면과 같이 출력해주세요.
년도 SA_REP SH_CLERK ST_CLERK 행의합
---------- -------------------- -------------------- -------------------- ------------------------------------------
2003 ₩0원 ₩0원 ₩7,100원 ₩7,100원
2004 ₩39,500원 ₩8,200원 ₩3,300원 ₩51,000원
2005 ₩74,800원 ₩15,400원 ₩18,100원 ₩108,300원
2006 ₩59,100원 ₩21,900원 ₩15,900원 ₩96,900원
2007 ₩38,200원 ₩13,400원 ₩6,900원 ₩58,500원
2008 ₩38,900원 ₩5,400원 ₩4,400원 ₩48,700원
열의합 ₩250,500원 ₩64,300원 ₩55,700원 ₩370,500원
select nvl(년도,'열의합') 년도,
to_char(nvl(SA_REP,0),'L999,999')||'원' SA_REP,
to_char(nvl(SH_CLERK,0),'L999,999')||'원' SH_CLERK,
to_char(nvl(ST_CLERK,0),'L999,999')||'원' ST_CLERK,
to_char(행의합,'L999,999')||'원' 행의합
from (select 년도, nvl(job_id,'x') job_id, sum_sal --여기서 행의합 열에 null값이 들어가지 않게 해주는 작업
from (select to_char(hire_date,'yyyy') 년도, job_id, sum(salary) sum_sal
from employees
where job_id in ('SA_REP','SH_CLERK','ST_CLERK')
group by cube(to_char(hire_date,'yyyy'), job_id)))
pivot(max(sum_sal) for job_id in ('SA_REP' "SA_REP", 'SH_CLERK' "SH_CLERK",'ST_CLERK' "ST_CLERK", 'x' "행의합"))
order by 1;
★계층 검색(hierarchical query) --분석할 때 많이 쓰임
예)
SELECT employee_id, last_name, manager_id
FROM employees;
100
101
108 200 203 204 205
109 110 111 112 113 206
SELECT employee_id, last_name, manager_id
FROM employees
START WITH employee_id = 101 --시작점, 시작해야 할 조건을 생성
CONNECT BY PRIOR employee_id = manager_id; --연결고리 조건-계층 검색은 위의 예를 보면서 설명을 하면 100이라는 가장 높은 계급의 사원이자 관리자가 있을 때 , 100을 관리자로 하는 사원(101)을 찾는다. 다음 101을 관리자로 하는 사원(108)을 찾는다. 다음 108을 관리자로 하는 사원(109)을 찾는다. 다음 109를 관리자로 하는 사원을 찾는데 없으면 다시 108을 관리자로 하는 사원(110)을 찾는다....... 이런 식으로 해당 사원을 관리자로 하는 사원을 하나씩 찾아내서 결과를 표출해주는 시스템이다.
- 코드를 보면 START WITH는 시작점으로 employee_id가 101인 사원부터시작해서 찾는다는 의미이고, CONNECT BY PRIOR은 연결고리 조건으로 employee_id와 manager_id로 찾는다.
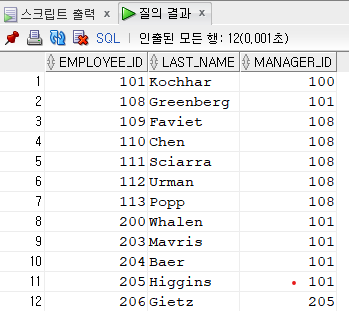
>하향식 (top-down방식, 위에서 아래로)
SELECT employee_id, last_name, manager_id
FROM employees
START WITH employee_id = 108 --시작점, 시작해야 할 조건을 생성
CONNECT BY PRIOR employee_id = manager_id; --연결고리 조건
-------------------------->
>상향식 (bottom-up방식, 밑에서 위로)
SELECT employee_id, last_name, manager_id
FROM employees
START WITH employee_id = 100 --시작점, 시작해야 할 조건을 생성
CONNECT BY employee_id = PRIOR manager_id; --연결고리 조건
<----------------------------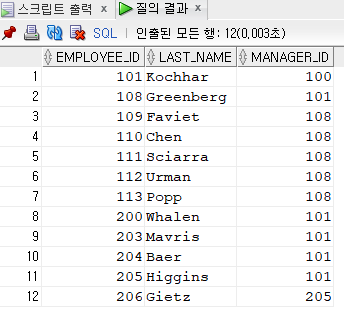
- 일반적으로 실행했을때는 하향식으로 나오는데 connect by prior employee_id = manager_id에서 연결 조건을 prior manager_id로 해주면 상향식으로 반대로 검색한다.
-위의 결과는 깔끔하게 보이지 않기 때문에 조금 구별해볼 것이다.
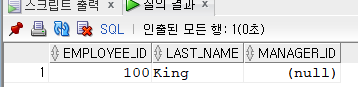
SELECT LEVEL, employee_id, last_name, manager_id --LEVEL 계층검색에서 사용되는 형태
FROM employees
START WITH employee_id = 100
CONNECT BY PRIOR employee_id = manager_id;
--밑의 형식처럼 계층별로 보이고 싶을때 어떻게 해야할까
100
101
108
109
110
111
112
113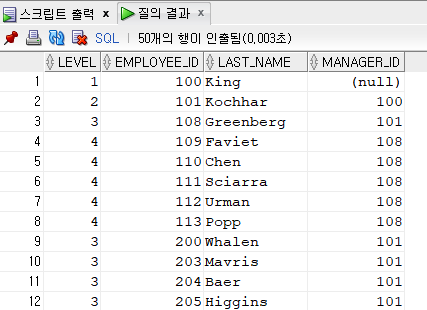
-level은 계층별로 보여줄 때 나타내기 좋은 함수이다. 100번 사원이 최고 관리자라고 했을 때 위의 형태처럼 계급별로 숫자가 붙는다.
SELECT LEVEL, lpad(' ',2*level-2,' ') || last_name
FROM employees
START WITH employee_id = 100
CONNECT BY PRIOR employee_id = manager_id;
- level함수와 lpad함수를 이용해서 보기 좋게 만들 수 있었다. lpad( 컬럼이름(or 문자, 숫자), 자릿수, 남은 부분 채울 것)
SELECT LEVEL, lpad(' ',2*level-2,' ') || last_name, employee_id, manager_id
FROM employees
WHERE employee_id != 101 --101번 사원만 제외
START WITH employee_id = 100
CONNECT BY PRIOR employee_id = manager_id
ORDER SIBLINGS BY last_name; -- 계층 검색된 내용을 정렬할 때는 siblings 옵션을 설정해야 하고 위치표기법은 사용할 수 없다.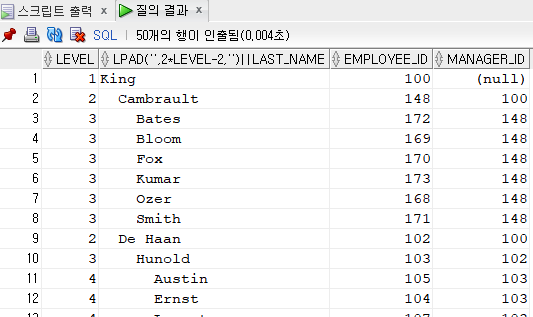
- 101번 사원과 101번을 관리자로 두고 있는 사람들을 제외하고 출력하고 싶다? 여기서 where절에 employee_id != 101을 하게 되면 101번 사원은 제외가 되는데 그를 관리자로 두고 있는 나머지 부하직원들은 제외되지 않는다. 그리고 order siblings by 절은 계층 검색된 내용을 정렬할 수 있다.
SELECT LEVEL, lpad(' ',2*level-2,' ') || last_name
FROM employees
START WITH employee_id = 100
CONNECT BY PRIOR employee_id = manager_id
--ORDER SIBLINGS BY last_name -- 계층 검색된 내용을 정렬할 때는 siblings 옵션을 설정해야 하고 위치표기법은 사용할 수 없다.
AND employee_id != 101;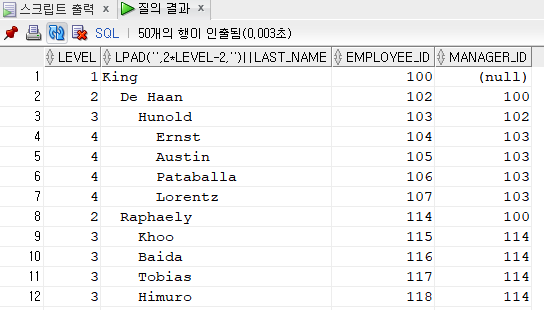
- connect by prior에서 조건으로 employee_id !=101;를 했을 때 101과 그 아래 부하직원들까지 모두 제외된다.
>level 응용하기1<
[문제 89] select 문을 이용해서 1~100 출력해주세요.
SELECT level
FROM dual
connect by level <=100;
[문제 90] select문을 이용해서 2단을 출력해주세요.
2단
---
2 * 1 = 2
2 * 2 = 4
...
2 * 9 = 18
SELECT '2 * '|| level || ' = ' || 2 * level "2단"
FROM dual
CONNECT BY level <= 9;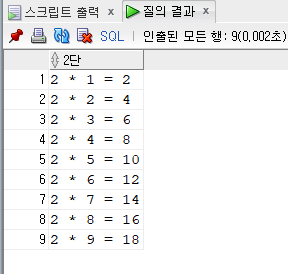
[문제 91] 구구단출력
SELECT 2 || ' * '|| level || ' = ' || 2 * level "2단",
3 || ' * '|| level || ' = ' || 3 * level "3단",
4 || ' * '|| level || ' = ' || 4 * level "4단",
5 || ' * '|| level || ' = ' || 5 * level "5단",
6 || ' * '|| level || ' = ' || 6 * level "6단",
7 || ' * '|| level || ' = ' || 7 * level "7단",
8 || ' * '|| level || ' = ' || 8 * level "8단",
9 || ' * '|| level || ' = ' || 9 * level "9단"
FROM dual
CONNECT BY level <=9;
SELECT dan || '*' || num || ' = ' || dan*num 구구단
FROM (SELECT level + 1 dan
FROM dual
CONNECT BY level <= 8),
(SELECT level num
FROM dual
CONNECT BY level <= 9); --카티션곱을 발생시켜서 작업하는 방식
- 두 번째 식이 더 깔끔하고 보기도 좋다. inline view(가상테이블)를 사용해서 하나는 1~9까지 또 하나는 2~9까지 두 개의 inline view를 만들고 카티션곱으로 계산이 되도록 한다.
■ 유저 관리
권한(privilege)
- 특정한 SQL문을 수행할 수 있는 권리
- 시스템 권한 : 데이터베이스에 영향을 줄 수 있는 권한
- 객체 권한 : 객체를 사용할 수 있는 권한
- ROLE(롤) : 유저에게 부여할 수 있는 권한을 모아 놓은 객체, 유지관리에 대한 편리성
- 내가 받은 시스템권한을 확인
SELECT * FROM user_sys_privs; --내가 받은 시스템권한을 확인
(create session 가장 중요한 권한)
- 내가 받은 또는 내가 부여한 객체권한을 확인
SELECT * FROM user_tab_privs;
- 내가 받은 롤을 확인
SELECT * FROM session_roles;
- 내가 받은 롤안에 시스템 권한을 확인
SELECT * FROM role_sys_privs;
- 내가 받은 롤안에 객체권한을 확인
SELECT * FROM role_tab_privs;
- 내 것 보기
SELECT * FROM user_users;
■ table 생성(object, segment)
- 데이터를 저장하는 객체
- 행과 열로 구성되어 있다.
※테이블을 생성하려면 두가지를 체크해야한다.
1. 테이블을 생성할 수 있는 권한
create table 시스템권한
select * from session_privs;
2. 테이블을 저장할 수 있는 테이블스페이스 권한
select * from user_ts_quotas; --hr(일반유저)입장에서 확인
select * from dba_ts_quotas; -- sys입장에서 확인(dba에서 실행가능,hr에서 실행불가)

★dba에서 체크(hr이 아님)
show user
- 데이터베이스에 생성된 유저 정보
SELECT * FROM dba_users;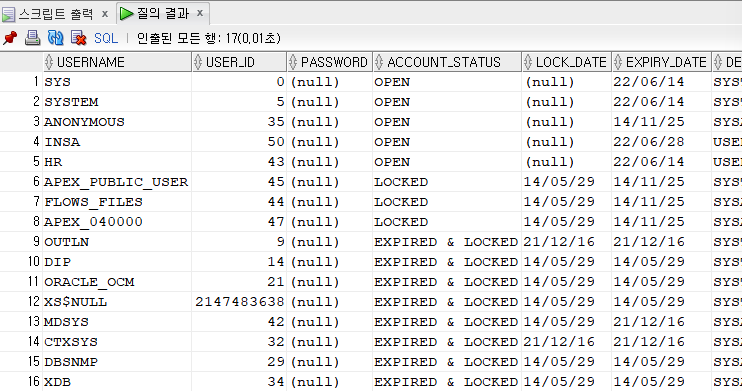
- 시스템권한을 어떤 유저한테 부여 했는지 확인
SELECT * FROM dba_sys_privs WHERE grantee ='HR';
- 객체권한을 어떤 유저한테 부여 했는지 확인
SELECT * FROM dba_tab_privs WHERE grantee = 'HR';
- 데이터베이스에 생성된 롤에 대한 정보 확인
SELECT * FROM dba_roles;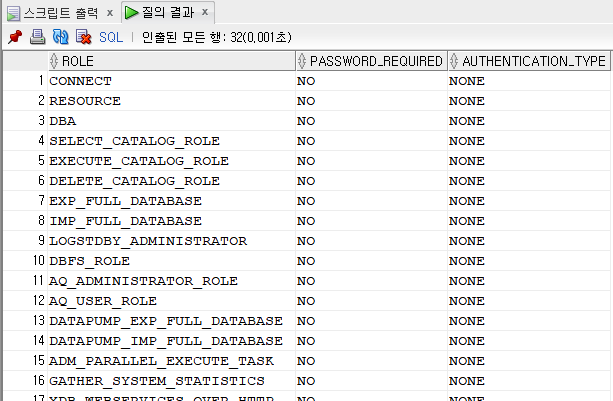
- 유저한테 부여한 롤에 대한 정보 확인
SELECT * FROM dba_role_privs WHERE grantee = 'HR';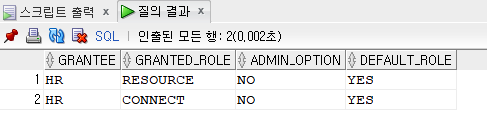
SELECT *
FROM dba_tables
WHERE table_name = 'EMPLOYEES'
AND owner = 'HR';
SELECT * FROM dba_data_files; --데이터파일들의 위치정보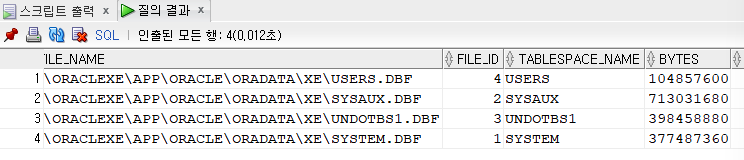
SELECT * FROM dba_temp_files;
SELECT *
FROM hr.employees
ORDER BY employee_id desc;
- 정렬작업 수행할 때 메모리에 수행 다 못하면 디스크로 내려 가야한다.
오라클 데이터베이스에 데이터를 저장하는 구조
논리적 물리적
database os
tablespace --<-data file -- 업무별로 분리가 되어 있다.
segment(table,index)
extent
block os block
block : 오라클의 최소 INPUT/OUTPUT 단위, 2K, 4K, 8K(기본값), 16K
책 = table(segment)
장 = extent
페이지 = block
문장(단어) = row
★유저생성
CREATE user james
identified by james
default tablespace users -- 테이블 생성시 사용할 수 있는 테이블 스페이스
temporary tablespace temp --정렬작업시 메모리에서 다 할 수 없으면 데이터를 임시로 저장하는 공간
quota 10m on users; -- tablespace를 사용할 수 있는 권한
SELECT * FROM dba_users WHERE username = 'JAMES'; --대소문자 구분해야하는 점
SELECT * FROM dba_ts_quotas;

★권한 부여
DCL(Data Control Language)
- grant : 권한 부여
- revoke : 권한 회수
- create session 권한을 유저한테 부여 하는 방법
grant create session to james; --james에게 권한 부여
--grant 시스템 권한 to 유저이름;
select * from dba_sys_privs where grantee = 'JAMES';
--james의 권한 확인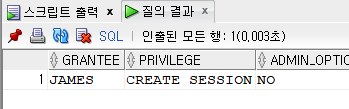
- 시스템권한을 유저로부터 회수하는 방법
revoke create session from james;
-- revoke 시스템권한 from 유저이름;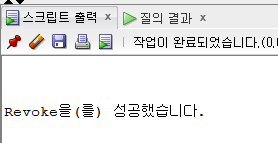
select * from dba_sys_privs where grantee = 'JAMES';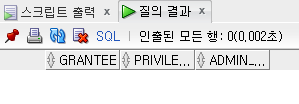
★유저 삭제
drop user james;
select * from dba_users where username = 'JAMES';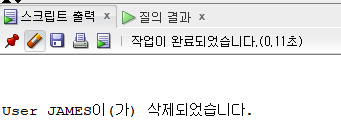

[문제92] 새로운 유저를 생성해주세요.
유저이름 : insa
비밀번호 : oracle
DEFAULT TABLESPACE : users
TEMPORARY TABLESPACE : temp
users TABLESPACE 사용량 : 1M
CREATE USER insa
IDENTIFIED BY oracle
DEFAULT TABLESPACE users
TEMPORARY TABLESPACE temp
QUOTA 1m ON users;
SELECT * FROM dba_users WHERE username = 'INSA'; --확인
[문제93] insa 유저에서 create session 권한을 부여 해주세요
GRANT CREATE SESSION TO insa;
SELECT * FROM dba_sys_privs WHERE grantee = 'INSA'; --확인
유저 정보 수정
ALTER USER insa
IDENTIFIED BY insa
DEFAULT TABLESPACE users
TEMPORARY TABLESPACE temp
QUOTA 1m ON users;
select * from dba_ts_quotas;
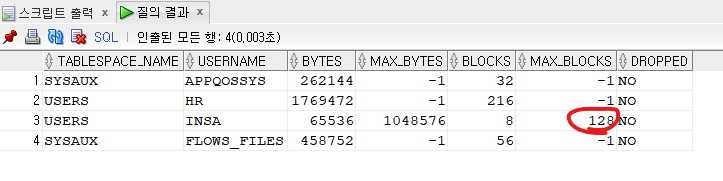
1.
ALTER user insa
QUOTA unlimited ON users;
2.
ALTER user insa
QUOTA 0 ON users;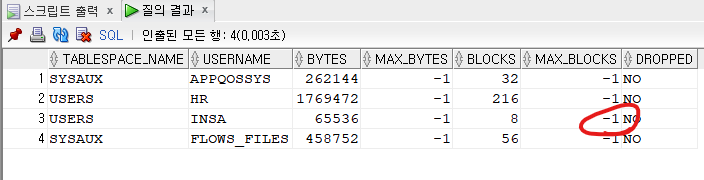
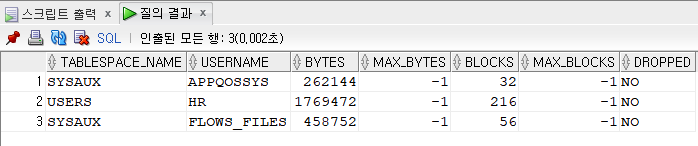
grant create table to insa;
select * from dba_sys_privs where grantee = 'INSA';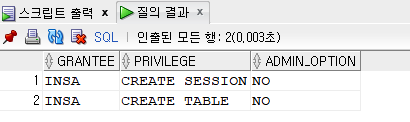
- create table 시스템 권한을 유저한테 회수
revoke create table from insa;
★다시 hr로 컴백
★ 테이블 이름, 칼럼 이름, 유저 이름, 다른 객체 이름, 제약조건 이름
- 문자로 시작(숫자로 시작 x)
- 문자의 길이는 1~30
- 문자, 숫자, 특수문자(_,#,$) 가능하다.
- 대소문자 구분하지 않습니다.
- 동일한 유저가 소유한 객체 이름은 중복되면 안 된다. --hr.emp, insa.emp
- 예약어는 사용할 수 없다.(select, distinct,...)
★ 칼럼의 타입
(desc employees -- 컬럼 타입 확인)
- number(p, s) : 가변 길이 숫자 타입, p : 전체자리수, s : 소수점자리수, number(5,2) --전체 5자리중에 소수점은 2자리를 사용하겠다
- varchar2(4000) : 가변길이 문자 타입 --쓰는 만큼만 , 최대 4000까지 사용 가능
- char(2000) : 고정길이 문자 타입 --고정적
- date : 날짜 타입
- clob : 가변 길이 문자 타입, 4 gbyte(기가바이트)
- blob : 가변길이 이진 데이터 타입, 4gbyte(기가바이트)
- bfile : 외부 파일에 저장된 이진 데이터 타입, 4 gbyte (이미지 같은 것은 주로 bfile을 사용, 실제 가지고 있는 것은 os)
★테이블 생성
create table hr.emp(
id number(4),
name varchar2(30),
day date default sysdate);
hr.emp 테이블은 어느 테이블스페이스에 저장이 되나요??
테이블을 생성하실때 테이블스페이스를 지정하지 않으면 유저 생성시에 설정한
default tablespace에 저장된다.
select * from user_tables where table_name = 'EMP';
- 테이블 삭제
drop table hr.emp purge;
create table hr.emp(
id number(4),
name varchar2(30),
day date default sysdate)
tablespace users; -- 테이블스페이스를 직접지정해주기
select * from user_tables where table_name = 'EMP';
★DML(Data Manipulation Language)
- insert(입력)
- update(수정)
- delete(삭제)
- merge(insert, update, delete)
★TCL(Transaction Control Language)
- commit(DML 영구히 저장하겠다)
- rollback(DML 영구히 취소하겠다)
- savepoint(rollback 기능을 도와주는 표시자)
★Transaction(트랜잭션) : 논리적으로 DML을 하나로 묶어서 처리하는 작업 단위
★insert문
-테이블에 새로운 행을 입력하는 sql문
desc emp --insert 하기 전에 테이블의 구조를 확인한 후에 insert문을 생성하자'
insert into 소유자.테이블(컬럼,컬럼,...) --내소유자면 안 써도되고 남의 소유면 써야함
values(데이터,데이터,..);
insert into hr.emp(id, name,day)
values(1,'홍길동', to_date('2021-12-16', 'yyyy-mm-dd')); --행 삽입
select * from hr.emp; --확인(미리보기) ->영구히 저장은 x ->sqlplus에서 안보임
commit; --영구히 저장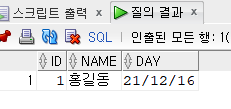
insert into hr.emp(id,name,day) -- transaction 시작
values(2,'박찬호', sysdate);
select * from hr.emp; --미리보기
insert into hr.emp(id,name,day)
values(3,'윤건',to_date('2021-11-20', 'yyyy-mm-dd'));
select * from hr.emp; --미리보기
commit; --transaction 종료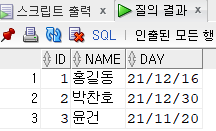
insert into hr.emp(id,name,day) -- transaction 시작
values(4,'나얼',to_date('2020-1-10', 'yyyy-mm-dd'));
select * from emp;
rollback; --영구히 취소, transaction 종료

--day컬럼에 default 값이 구성되어 있으면 default값이 입력된다.
-- insert를 수행하는 시점에 default값으로 구성된 sysdate값이 입력된다.
insert into hr.emp(id,name)
values(5,'이문세');
insert into hr.emp(id,name,day)
values(6,'손흥민',default);
select * from emp;
commit;
# null값을 입력하는 밥법
insert into hr.emp(id,name,day)
values(7,'하든',null); --day 컬럼에 default값이 설정되어있더라도 null이 우선순위가 높다. 강사님이 좋아하는 nba농구선수
select * from emp; --미리보기
insert into hr.emp(id,name,day)
values(8,null,null);
select * from emp;--미리보기
commit; --커밋하기 전에 미리보기로 먼저 확인 완료하고 완벽히 되면 커밋하도록
rollback; --이미 transaction을 commit을 수행했기때문에 rollback을 수행해도 의미가 없다.
select * from hr.emp;
-commit을 하고 나고 rollback을 했을 때 rollback은 효과가 없다.
★ update
- 특정한 필드 값을 수정하는 SQL문
update 소유자.테이블
set 수정할 필드가 있는 컬럼 = 새로운 값
where 조건;
update hr.emp -- transaction 시작
set day = to_date('2002-01-01', 'yyyy-mm-dd');
select * from hr.emp; -- 미리보기
rollback; --영구히 취소, transaction 종료
select * from hr.emp;update hr.emp
set day = to_date('2001-01-01','yyyy-mm-dd')
where id =1;
select * from hr.emp; --미리보기
commit;
-- 여러컬럼의 필드값을 수정
update hr.emp
set name = '커리', day = default
where id = 8;
select * from hr.emp where id = 8;
commit;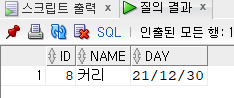
- null값으로 수정(행에 있는 필드 값들)
update hr.emp
set day = null
where id =2;
select * from hr.emp;
commit;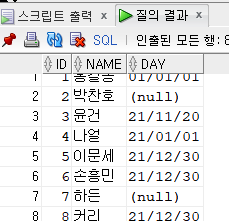
★ delete문
- 행을 삭제하는 SQL문
delete from 소유자.테이블;
delete from 소유자.테이블 where 삭제해야할 행의 조건;
delete from hr.emp; --전체행 다 삭제됨
select * from hr.emp;
rollback;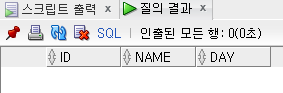
-delete from hr.emp 수행했을 때 hr.emp테이블에 있는 모든 행이 삭제된다. commit을 안 했기 때문에 rollback으로 되돌릴 수 있다.
delete from hr.emp
where id = 1;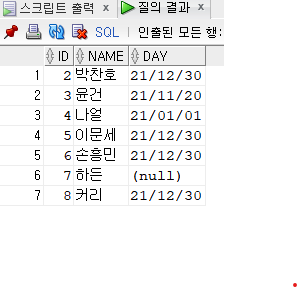
delete from hr.emp where id in (2,3,4);
select * from hr.emp;
rollback;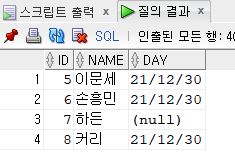
'SQL' 카테고리의 다른 글
| 2022.1.5 오늘의 공부 (0) | 2022.01.06 |
|---|---|
| 2022.1.4 오늘의 공부 (0) | 2022.01.05 |
| 12.29 오늘의 공부 (0) | 2021.12.29 |
| 12.28 오늘의 공부 (0) | 2021.12.28 |
| 12.27 오늘의 공부 (0) | 2021.12.27 |