더보기
▣오늘의 주요 키워드▣
- 집합연산자
- 합집합
- 교집합
- 차집합
- rollup
- cube
- grouping sets
>복습 문제
[문제81] 아래 화면과 같이 출력해주세요.
년도 SA_REP SH_CLERK ST_CLERK
-------- -------------------- -------------------- --------------------
2001 ₩0원 ₩0원 ₩0원
2002 ₩0원 ₩0원 ₩0원
2003 ₩0원 ₩0원 ₩7,100원
2004 ₩39,500원 ₩8,200원 ₩3,300원
2005 ₩74,800원 ₩15,400원 ₩18,100원
2006 ₩59,100원 ₩21,900원 ₩15,900원
2007 ₩38,200원 ₩13,400원 ₩6,900원
2008 ₩38,900원 ₩5,400원 ₩4,400원
1)decode
select to_char(hire_date, 'yyyy') 년도,
to_char(nvl(sum(decode(job_id, 'SA_REP', salary)),0), 'l999,999') || '원' "SA_REP",
to_char(nvl(sum(decode(job_id, 'SH_CLERK', salary)),0), 'l999,999') || '원' "SH_CLERK",
to_char(nvl(sum(decode(job_id, 'ST_CLERK', salary)),0), 'l999,999') || '원' "ST_CLERK"
from employees
--where job_id in ('SA_REP', 'SH_CLERK', 'ST_CLERK') --2개의 job_id가 입사하지 않은 열은 빼고 수행
group by to_char(hire_date, 'yyyy')
order by 1;
2)pivot
select 년도, to_char(nvl(SA_REP,0),'l999,999') || '원' "SA_REP",
to_char(nvl(SH_CLERK,0),'l999,999') ||'원' "SH_CLERK",
to_char(nvl(ST_CLERK,0),'l999,999') ||'원' "ST_CLERK"
from (select to_char(hire_date, 'yyyy') 년도, job_id, salary
from employees)
pivot (sum(salary) for job_id in ('SA_REP' "SA_REP" , 'SH_CLERK' "SH_CLERK", 'ST_CLERK' "ST_CLERK"))
order by 1;
-81번 문제의 포인트는 pivot함수 사용법과, nvl함수를 이용하여 null값을 0으로 변경하고 원단위, 컴마 표기 사용법이다.
★집합 연산자
-select절의 칼럼의 개수가 일치해야 한다.
- 첫 번째 select절의 칼럼의 대응되는 두번째 select절 컬럼의 데이터 타입이 일치해야 한다.
- union, intersect, minus 연산자는 중복을 제거한다.
- union, intersect, minus 연산자는 중복을 제거하기 위해서 정렬이 수행된다.
- 집합 연산자에서 order by 절은 제일 마지막에 기술해야 한다.
- order by 절에는 첫 번째 select절의 칼럼 이름, 별칭, 위치 표기법을 사용한다.
※주의 : 칼럼의 별칭을 사용하면 무조건 별칭, 위치 표기법만 사용해야 한다.
★합집합
-union : 중복제거
-union all : 중복 포함
select employee_id, job_id, salary
from employees
union
select employee_id, job_id, null --0 --to_number('0')
from job_history; --job_id를 한번이라도 변경한 사원들이 있는 테이블
select employee_id id, job_id, salary
from employees
union all
select employee_id, job_id, null --0 --to_number('0')
from job_history --job_id를 한번이라도 변경한 사원들이 있는 테이블
order by 1; --컬럼에 별칭을 썼을 때 컬럼이름을 사용하지 못하고 별칭만 사용가능, 위치표기법은 그냥 사용가능
★교집합
-intersect
select employee_id, job_id
from employees
intersect
select employee_id, job_id
from job_history;
1
select employee_id, job_id
from employees
where employee_id =176;
2
select employee_id, job_id
from job_history
where employee_id =176;

-여기서 중요한 점은 176번 사원은 SA_REP에서 근무했다가 SA_MAN으로 이동해서 근무했다가 다시 SA_REP에서 근무하고 있는 사원이다
★차집합
-MINUS
select employee_id
from employees
minus
select employee_id
from job_history;
-employees테이블에서 job_history테이블에 있는 employee_id가 같거나 job_history에만 있는 employee_id는 빼고 employees테이블에만 있는 employee_id를 출력한다.
[문제82] job_id를 한번이라도 바꾼 사원들의 정보를 출력해주세요.
1)집합연산자 --시스템에서 자동으로 정렬해야하는 성능상의 문제점
SELECT *
FROM employees
WHERE employee_id in (SELECT employee_id
FROM employees
intersect
SELECT employee_id
FROM job_history);
2)exists --현장에서는 이렇게 코드를 짜야함
SELECT *
FROM employees e
WHERE exists (SELECT 'x'
FROM job_history
WHERE employee_id = e.employee_id);
[문제 82] job_id를 바꾸지 않은 사원들의 정보를 출력해주세요
1) 집합연산자
SELECT *
FROM employees
WHERE employee_id in (SELECT employee_id
FROM employees
minus
SELECT employee_id
FROM job_history);
2)not exists 연산자 -- 더 효율성이 높음
SELECT *
FROM employees e
WHERE not exists (SELECT 'x'
FROM job_history
WHERE employee_id = e.employee_id);
[문제84] 부서가 소재하지 않은 국가의 리스트가 필요합니다. country_id, country_name 출력해주세요.
1)집합
SELECT country_id, country_name
FROM countries
MINUS
SELECT c.country_id, c.country_name
FROM departments d, locations l, countries c
WHERE d.location_id = l.location_id
and l.country_id = c.country_id;
2)not exists
select country_id, country_name
from countries c
where not exists(select 'x'
from departments d, locations l
where d.location_id = l.location_id
and l.country_id = c.country_id);
[문제85] union ->union all + not exists
1)
select e.employee_id, e.last_name, d.department_name
from employees e, departments d
where e.department_id(+)= d.department_id(+); --실행안됨 양쪽 다 아우터조인을 할 수 없음
2)
select e.employee_id, e.last_name, d.department_name
from employees e, departments d
where e.department_id= d.department_id(+)
union
select e.employee_id, e.last_name, d.department_name
from employees e, departments d
where e.department_id(+)= d.department_id;
3)
답)
select e.employee_id, e.last_name, d.department_name
from employees e, departments d
where e.department_id= d.department_id(+)
union all
select null, null, department_name --소속 사원이 없는 부서추출하기
from departments d
where not exists ( select 'x'
from employees
where department_id = d.department_id);
--동일한 테이블을 두번씩 수행하는 문제가 있음
>ANSI버전으로 하면 이렇게 간단히 할 수 있는데 ANSI를 사용하지 않는 회사들도 있다.(테이블을 두번씩들어가는 문제를 직접 말씀드리는 것)
select e.employee_id, e.last_name, d.department_name
from employees e full outer join departments d
on e.department_id= d.department_id;
[문제 86]
1)DEPARTMENT_ID, JOB_ID, MANAGER_ID 기준으로 총액 급여를 출력
SELECT sum(salary)
FROM employees
GROUP BY department_id, job_id, manager_id;
2) department_id, job_id 기준으로 총액급여를 출력
SELECT sum(salary)
FROM employees
GROUP BY department_id, job_id;
3) department_id 기준으로 총액급여를 출력
SELECT sum(salary)
FROM employees
GROUP BY department_id;
4) 전체 총액 급여를 출력
SELECT sum(salary)
FROM employees;
1),2),3),4)를 한꺼번에 출력해주세요.
SELECT department_id, job_id, manager_id, sum(salary)
FROM employees
GROUP BY department_id, job_id, manager_id
union all
SELECT department_id, job_id, null, sum(salary)
FROM employees
GROUP BY department_id, job_id
union all
SELECT department_id, null,null ,sum(salary)
FROM employees
GROUP BY department_id
union all
SELECT null, null, null, sum(salary)
FROM employees;
★rollup 연산자
-group by절 지정된 열 리스트를 오른쪽에서 왼쪽 방향으로 이동하면서 그룹화를 만드는 연산자
예)
select a,b,c,sum(sal)
from test
group by a,b,c;
sum(sal) = {a,b,c}
예)
select a,b,c,sum(sal)
from test
group by rollup(a,b,c);
sum(sal) = {a,b,c}
sum(sal) = {a,b}
sum(sal) = {a}
sum(sal) = {}
SELECT department_id, job_id, manager_id, sum(salary)
FROM employees
GROUP BY rollup(department_id, job_id, manager_id);
-rollup의 칼럼에 그룹 함수 빼고는 다 있어야 한다.
★cube 연산자
-rollup연산자를 포함하고 (조합 가능한) 모든 그룹화 할 수 있는 것을 만드는 연산자.
예)
select a,b,c,sum(sal)
from test
group by cube(a,b,c);
sum(sal) = {a,b,c}
sum(sal) = {a,b}
sum(sal) = {a,c}
sum(sal) = {b,c}
sum(sal) = {a}
sum(sal) = {b}
sum(sal) = {c}
sum(sal) = {}
SELECT department_id, job_id, manager_id, sum(salary)
FROM employees
GROUP BY cube(department_id, job_id, manager_id);
★grouping sets 연산자(9i)
- 내가 원하는 그룹을 만드는 연산자
예)
select a,b,c,sum(sal)
from test
group by grouping sets((a,b), (a,c), ());
sum(sal) = {a,b}
sum(sal) = {a,c}
sum(sal) = {}
SELECT department_id, job_id, manager_id, sum(salary)
FROM employees
GROUP BY grouping sets((department_id, job_id),(department_id, manager_id),());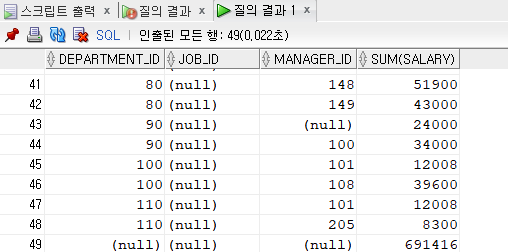
[문제87] 년도 분기별 총액을 구하세요. 행의 합과 열의 합도 구하세요.
YEAR 1분기 2분기 3분기 4분기 합
---- ---------- ---------- ---------- ---------- ----------
2001 17000 17000
2002 36808 21008 11000 68816
2003 35000 8000 3500 46500
2004 40700 14300 17000 14000 86000
2005 86900 16800 60800 33400 197900
2006 69400 20400 14200 17100 121100
2007 36600 20200 2500 35600 94900
2008 46900 12300 59200
297500 155808 123508 114600 691416
1)decode
select year,
max(decode(quarter,1, sum_sal)) "1분기", -- sum_sal에 영향을 주지않는 그룹함수 max나 min을 사용, 그룹함수를 적용하지 않으면 group by절에 들어가야하기 때문에 decode함수를 그대로 넣어주기에는 좋지않다?
max(decode(quarter,2, sum_sal)) "2분기",
max(decode(quarter,3, sum_sal)) "3분기",
max(decode(quarter,4, sum_sal)) "4분기",
max(decode(quarter,null,sum_sal)) "합"
from (select to_char(hire_date, 'yyyy') year, to_char(hire_date, 'q') quarter, sum(salary) sum_sal
from employees
group by cube(to_char(hire_date, 'yyyy'), to_char(hire_date, 'q')))
group by year
order by 1;
2)pivot
select *
from (select year, nvl(quarter,0) quarter, sum_sal
from (select to_char(hire_date, 'yyyy') year, to_char(hire_date, 'q') quarter, sum(salary) sum_sal
from employees
group by cube(to_char(hire_date, 'yyyy'), to_char(hire_date, 'q'))))
pivot(max(sum_sal) for quarter in (1 "1분기",2 "2분기",3 "3분기",4 "4분기", 0 "행의 합")) --그룹함수를 무조건 써줘야하기에 값에 영향없는 max
order by 1;
2-1)pivot 최종
select nvl(year, '합계') year, nvl("1분기",0) "1분기", nvl("2분기",0) "2분기", nvl("3분기",0) "3분기", nvl("4분기",0) "4분기"
from (select year, nvl(quarter,0) quarter, sum_sal
from (select to_char(hire_date, 'yyyy') year, to_char(hire_date, 'q') quarter, sum(salary) sum_sal
from employees
group by cube(to_char(hire_date, 'yyyy'), to_char(hire_date, 'q'))))
pivot(max(sum_sal) for quarter in (1 "1분기",2 "2분기",3 "3분기",4 "4분기", 0 "행의 합")) --그룹함수를 무조건 써줘야하기에 값에 영향없는 max
order by 1;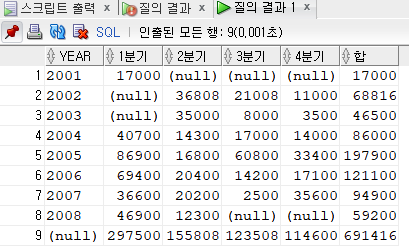

'SQL' 카테고리의 다른 글
| 2022.1.4 오늘의 공부 (0) | 2022.01.05 |
|---|---|
| 12.30 오늘의 공부 (0) | 2021.12.30 |
| 12.28 오늘의 공부 (0) | 2021.12.28 |
| 12.27 오늘의 공부 (0) | 2021.12.27 |
| 12.24 오늘의 공부 (0) | 2021.12.24 |