더보기
▣주요 키워드▣
- matrix
- array
- factor
- data frame
★ matrix(행렬)
- 수, 문자를 직사각형 형태로 나타낸 자료형
- 백터처럼 한 가지 유형의 타입만 저장한다.
- 행(가로)과 열(세로) 구성된다.
matrix(c(1:9))
matrix(c(1:9),nrow=3) #nrow : 행의수
matrix(c(1:9),ncol=3) #ncol : 열의수matrix(c(1:10),nrow=2,ncol=5)
matrix(c(1:10),nrow=5,ncol=2)x <- matrix(c(1:12), ncol=2,nrow=6)
x
str(x)
class(x)
mode(x)
typeof(x)
is.integer(x)
is.numeric(x)
is.list(x)
is.character(x)
is.matrix(x)dim(x) # 행렬의 크기, 6 x 2, 행의수 x 열의수
NROW(x) # 행의수
nrow(x) # 행의수
ncol(x) # 열의수
length(x) # 형렬 안에 들어 있는 값의 수
dim(x)[1] # 행의수
dim(x)[2] # 열의수z <- c(1:9)
length(z)
NROW(z)
nrow(z) # 벡터에서는 수행되지 않는다matrix(c(1:9),ncol=3) # byrow=FALSE : 열기준으로 값을 채움, 기본값
matrix(c(1:9),ncol=3,byrow=FALSE)
matrix(c(1:9),ncol=3,byrow=TRUE) # byrow=TRUE : 행기준으로 값을 채움x <- matrix(c(1,2,3,4),nrow=2,ncol=2,byrow=T,
dimnames=list(c('row1','row2'),
c('col1','col2'))) #행과 열에 이름을 입력
xclass(dimnames(x)) # list형식
dimnames(x)[1] # 행의 이름
dimnames(x)[[1]] # 페이지 이름 빼고 행의 이름만
dimnames(x)[2] # 열의 이름
dimnames(x)[[2]]▶행렬의 이름 수정
y <- matrix(c(1:9),ncol=3)
y
# 행렬의 이름 수정
dimnames(y) <- list(c('row1','row2','row3'),
c('col1','col2','col3'))
dimnames(y)
y▶행 이름 수정
# 행이름 수정
rownames(y) <- c('r1','r2','r3')
dimnames(y)[[1]] <-c('row1','row2','row3')
rownames(y)[2] <- 'r2' # 행의 두번째 이름만 변경
'r2' %in% rownames(y)
rownames(y) %in% 'r2'
which(rownames(y) %in% 'r2')
rownames(y) == 'r2'
which(rownames(y) %in% 'r2')
rownames(y)[which(rownames(y) %in% 'r2')] <- 'row2'
y
▶열 이름 수정
# 열이름 수정
colnames(y) <- c('c1','c2','c3')
dimnames(y)[[2]] <- c('col1','col2','col3')
colnames(y)[2] <- 'c2'
colnames(y)[which(colnames(y) %in% 'c2')] <- 'col2'
y
cell <- c(1:9)
rname <- c('a','b','c')
cname <- c('c1','c2','c3')
x <- matrix(cell,nrow=3,byrow=T,dimnames=list(rname,cname))
x
▶ 전차행렬(transposed matrix), 행과 열의 위치를 바꾼 행렬
cell <- c(1:9)
rname <- c('a','b','c')
cname <- c('c1','c2','c3')
x <- matrix(cell,nrow=3,byrow=T,dimnames=list(rname,cname))
x
t(x) # 전차행렬
x_t <- t(x)
x_t
rownames(x_t) <- rownames(x) # 행의 이름까지 열로 바뀌어 있어서 행의 이름은 다시 바꾸기
colnames(x_t) <- colnames(x) # 열의 이름까지 행으로 바뀌어 있어서 열의 이름은 다시 바꾸기
x_t
▶ 행렬의 인덱싱
x[1,1] #[행인덱스, 열인덱스]
x[1,2]
x[2,3]
x[2,] # [행인덱스,] 2행의 값들을 다 추출
x[,3] # [,열인덱스] 3열의 값들을 다 추출
x[-1,] # 첫번째 행을 제외시키고 추출 ( 특정한 행 제외)
x[,-2] # 두번째 열을 제외시키고 추출 ( 특정한 열 제외)
x[-1,-2] # 특정한 행, 열 제외
x[-1,] # 첫번째 행을 제외시키고 추출 ( 특정한 행 제외)
x[,-2] # 두번째 열을 제외시키고 추출 ( 특정한 열 제외)
x[-1,-2] # 특정한 행, 열 제외
x[c(1,3),] # 특정한 행들 추출
x[,c(2,3)] # 특정한 열들 추출
x[c(1,3),2] # 특정한 행과 열 추출
x['a',] # 행 이름으로 추출
x[,'c3'] # 열 이름으로 추출
x
which(x==10)
which(x==5) # 행렬 안에 값을 열기준으로 찾는다.
which(x==3)
which(x==6)
▶ 행렬의 연산
x <- matrix(c(1:4),ncol=2)
x
# 행렬의 연산
x+10
x-10
x*10
x/2
x%/%2 #몫
x%%2 #나머지
y <- matrix(c(5:8),ncol=2)
y
# 행렬의 같은 위치에 있는 성분끼리 연산 작업을 수행한다.
x+y
x-y
x*y
x/y
x%/%y
x%%y
▶ 행렬의 곱
x
y
x %*% y # 행렬의 곱 계산식
# 행렬의 곱 과정
1 3 %*% 5 7 = (1*5 + 3*6, 1*7 + 3*8)
2 4 6 8 (2*5 + 4*7, 2*7 + 4*8)
dim(x) # dim : 행과 열의 개수를 출력
dim(y)
2*2 2*2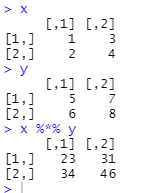
▶ 정방행렬(square matrix) : 같은 수의 행과 열을 가지는 행렬
2*2, 3*3, 4*4...
▶ 항등행렬(identity matrix), 단위행렬(unit matrix)
- 대각성분이 모두 1이고 그 이외의 모든 성분이 0인 정방 행렬
diag(4)
diag(3)
diag(2)
▶ 대각 행렬(diagonal matrix)
- 대각 성분이 아닌 모든 성분이 0인 행렬
a <- c(1:3)
diag(a)
diag(2,nrow=3)
diag(7,nrow=5)
▶ 역행렬(invertible matrix)
solve(x)
x %*% solve(x) # 단위행렬
▶ 열결합
x <- c(1:4)
y <- c(5:8)
x
y
z <- cbind(x,y) # 열결합
class(z)
z
r <- rbind(x,y) # 행결합
class(r)
r
▶ 행 제거
x <- matrix(c(1:18),nrow=6, byrow=FALSE)
x[-6,]
x <- x[-6,]
x
▶ 행, 열 수정
dim(x)
x
dim(x) <- c(3,5) # 5행 3열 -> 3행5열 수정 #c(행,열)
x
dim(x) <- c(1,15)
x
dim(x) <- c(15,1)
x
dim(x) <- c(5,3)
x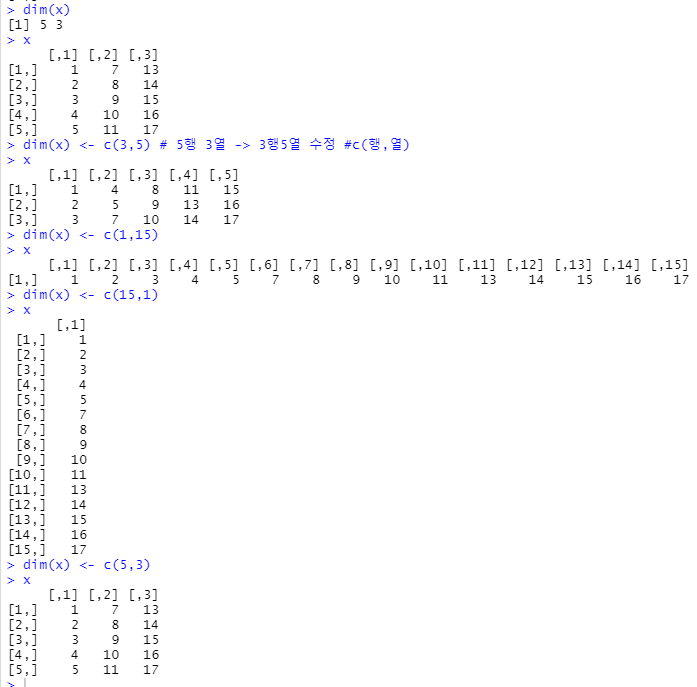
★ array(배열)
- 같은 데이터 타입을 갖는 3차원 배열구조
x <- array(c(1:9),dim=c(2,3))
x
class(x)
str(x)
mode(x)
is.matrix(x) # matrix확인 방법
is.array(x) # array 확인 방법
dim(x)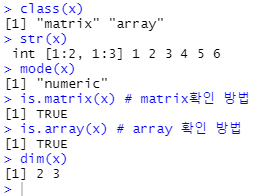
-배열과 행렬은 표현식이 조금 다르지만 거의 비슷하다고 볼 수 있다. 배열로 만든 x를 is.matrix(x)라고 해도 true가 나온 것처럼 거의 같다고 생각하면 된다.
y <- array(c(1:24),dim=c(2,3,4)) # dim=c(행,열,면면)
y
class(y)
mode(y)
str(y)
is.matrix(y)
is.array(y)
y[1,1,1] # [행,열,면]
y[,,1] # 특정한 면만 확인
dimnames(y) <- list(c('r1','r2'),c('c1','c2','c3')) # 열과 행에 이름 넣기
rownames(y)
colnames(y)
dimnames(y) <- NULL # 행과열의 이름을 다 지우기
y
y
dim(y) # array 모습 확인
dim(y) <- c(3,4,2) # 3행, 4열, 2면으로 바꾸기
y
★ factor
- 범주형 데이터를 표현하는 자료형
- (좋음, 보통, 나쁨), (남자, 여자), 거주지역, 혈액형
- 종류 : 순위형, 순서형(ordinal), 명목형(nominal)
x <- factor(c("보통","애매","좋음","나쁨"),levels=c("좋음","보통","나쁨")) #level에 있는 값들을 표현할 수 있음,없는값은 <na>출력
x
#구조확인
str(x)
class(x)
mode(x)
typeof(x)
y <- factor("보통",levels=c("좋음","보통","나쁨"),ordered=T) # 순위형 factor
y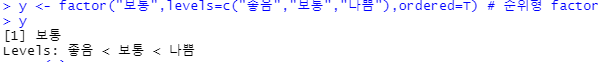
is.factor(x) #factor 형 체크
is.factor(y)
is.ordered(x) # 순위형 factor 체크
is.ordered(y)
nlevels(x) # factor level 수 확인
nlevels(y)
levels(x) # factor level 값 확인
levels(y)
levels(y)[1]
"좋음" %in% levels(y)
levels(y) %in% "좋음"
levels(y)[which(levels(y) %in% "좋음")] <- "매우좋음"
# levels(y)위치에서 좋음이 있는 자리는 매우좋음으로 변경
levels(y)
levels(y)[which(levels(y) %in% "보통")] <- "좋음"
y
levels(y) <- c('good','normal','bad') # factor level 값 수정정
y
levels(y)[2] <- '보통' # normal을 보통으로 변경(모든 normal값을 보통으로 변경)
y
y <- c('좋음','보통','그냥','나쁨','좋음','보통')
y
x <- factor(y,levels=c('나쁨','보통','좋음'))
x[is.na(x)] #na값 찾기
x[which(is.na(x))] <- '보통' #na값을 '보통'으로 수정
x
levels(x) == '좋음'
levels(x)[which(levels(x) %in% "좋음")] <- "매우좋음" #좋음을 매우좋음으로 수정
levels(x)[which(levels(x) =="좋음")] <- "매우좋음" # 좋음을 매우좋음으로 수정
is.factor(x) # factor형인지 확인
is.ordered(x) # ordered(순위)형인지 확인
x <- as.ordered(x) #순위형으로 바꾸기
is.ordered(x)
x
★ factor levels의 순서를 바꾸려면?
1. factor 형을 vector형으로 변환
y <- as.vector(x)
y
str(y)
2. vector 형을 factor형으로 변환
y <- factor(y,levels=c("매우좋음","보통","나쁨"),ordered=T)
y
is.ordered(y)
★ data frame
- 데이터베이스에 table과 유사
- 행과 열로 구성
- 서로 다른 데이터 타입을 갖는 2차원 테이블(배열) 구조
df <- data.frame(name=c('scott','hraden','curry'),
sql=c(90,80,70),
r=c(80,70,90))
df
str(df)
class(df)
mode(df)
typeof(df)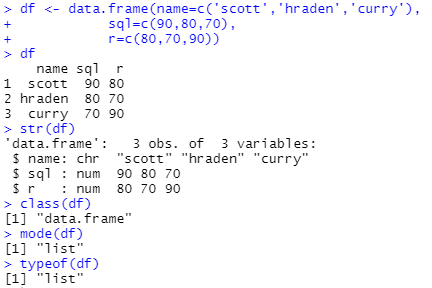
df$name # 특정한 컬럼 확인
df$sql
dim(df)
df[1,1]
df[2,1]
df[1,1] <- 'james' # 값을 수정
#sql에서 이렇게 표현
update df
set name = james
where name = 'scott'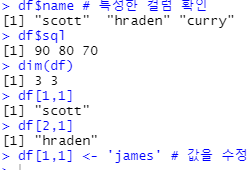
df[1,] # 특정한 행추출
df[,1] # 특정한 열추출
df[c(1,3),]
df[,'name']
df[,c('name','r')] # sql > select name,r from df;
df[,'name'] # 열을 하나 출력할 때는 기본값으로 가로 방향 출력, 벡터로 출력
df[,'name',drop=F] # drop=F옵션 세로 방향 출력, 데이터프레임으로 출력
df[,'name'][2]
class(df[,'name'])
df[,'name',drop=F][2,]
class(df[,'name',drop=F])
names(df) # 열이름 출력
colnames(df) # 열이름 출력
colnames(df) <- c('NAME', 'SQL','R') # 열이름 수정
df
rownames(df)
rownames(df) <- c('사원1','사원2','사원3') # 행이름 수정
df
rownames(df) <- NULL # 행이름 삭제
df
'SQL' %in% names(df) # SQL이 df(데이터프레임) 내에 변수명들 중 있으면 TRUE
'SQL' %in% colnames(df) # SQL이 df(데이터프레임)의 컬럼명들 중 있으면 TRUE
names(df) %in% 'SQL' # df(데이터프레임) 내에 있는 변수명들 각각을 비교해서 SQL이랑 이름이 같으면 TRUE 아니면 FALSE
colnames(df) %in% 'SQL'
names(df) %in% c('SQL','R')
colnames(df) %in% c('SQL','R')
c('SQL','PYTHON') %in% names(df) #SQL은 df(데이터프레임) 변수명들 중에 있어서 true가 줄력되고 PYTHON은 없기에 FALSE가 출력된다.
names(df) %in% c('SQL','PYTHON')
df[,'SQL']
df[,c('SQL','R')]
df[,c('SQL','PYTHON')] # 오류 (PYTHON은 정의되지 않은 열)
df[,names(df) %in% c('SQL','PYTHON','R')] # PYTHON이 없어도 TRUE값들만 출력, 특정한 열을 추출
df[,!names(df) %in% c('SQL','PYTHON','R')] # 특정한 열을 제외해서 추출
which(names(df) %in% c('SQL','PYTHON','R')) # SQL,PYTHON,R이 있는 위치를 찾아서 출력
which(!names(df) %in% c('SQL','PYTHON','R')) # SQL,PYTHON,R이 없는 위치를 찾아서 출력
which(names(df) == c('SQL','PYTHON','R')) # R은 나오는데 SQL은 안나옴 주의! (==은 여기서 사용되기에 알맞지 않음)
which(!names(df) == c('SQL','PYTHON','R')) # 반대로 없는 값 PYTHON말고 다른 것이 TRUE가 되면 안되는데 SQL이 TRUE가 되어서 값이 2개 나옴(마찬가지)
which(names(df) == 'SQL') | which(names(df) == 'PYTHON') | which(names(df) == 'R') # 값이 아예 안나옴
which(names(df) == 'SQL')
which(names(df) == 'PYTHON')
which(names(df) == 'R')
df$PYTHON <- c(90,70,60) # 새로운 컬럼을 추가
df
length(df) # 컬럼의 수
NROW(df) # 행의 수
nrow(df) # 행의 수
str(df)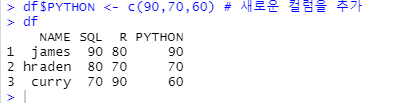

df <- data.frame(x=1:100000)
df
head(df,n=10) # 앞부분의 행 추출
tail(df,n=10) # 뒷부분의 행 추출출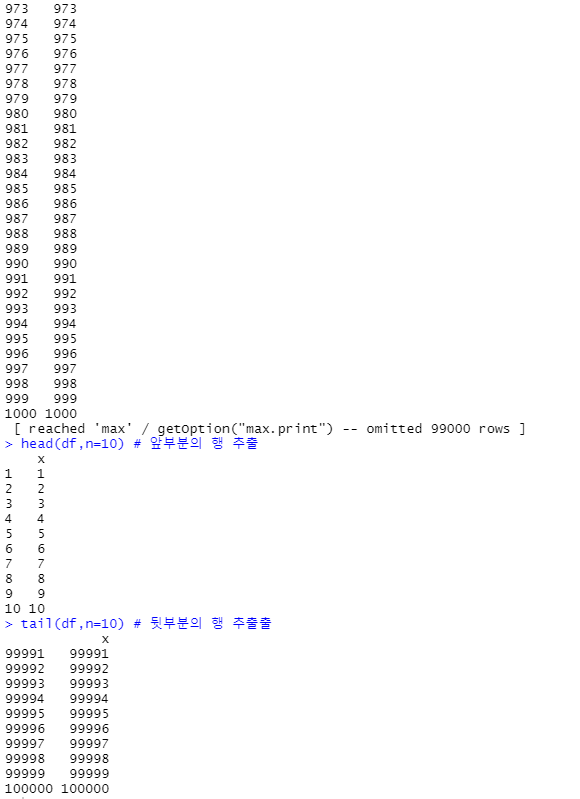
★ read.csv
-csv파일을 데이터 프레임으로 읽어 들이는 함수
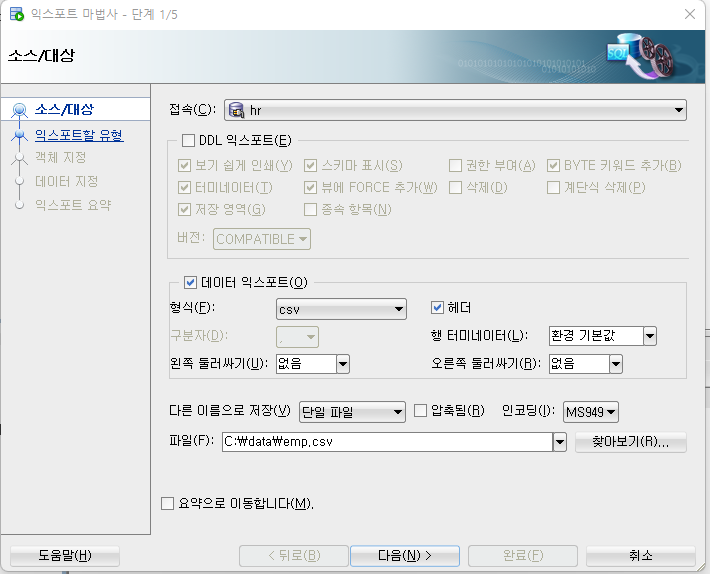
- 오라클 SQL Developer에서 '데이터베이스 익스포트'를 들어간다
- 익스포트 할 유형에서 DDL은 빼고 데이터 익스포트에서 형식을 csv, 헤더(칼럼 이름), 둘러싸기(없음, 큰따옴표도 종종 사용된다), 저장 위치를 설정한다.
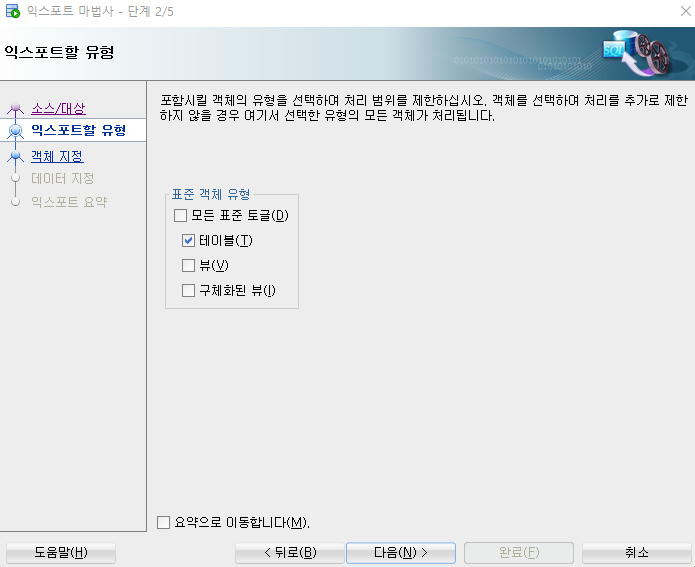
3. 표준 객체 유형을 테이블로 설정한다.
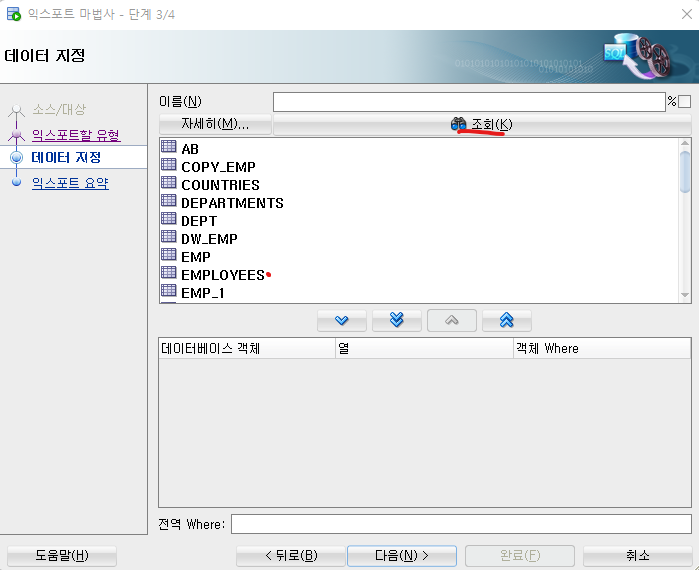
4. 데이터 지정에서 조회를 클릭하면 hr유저의 테이블들이 나온다. 여기서 내가 사용할 테이블인 EMPLOYEES를 밑으로 내린다.
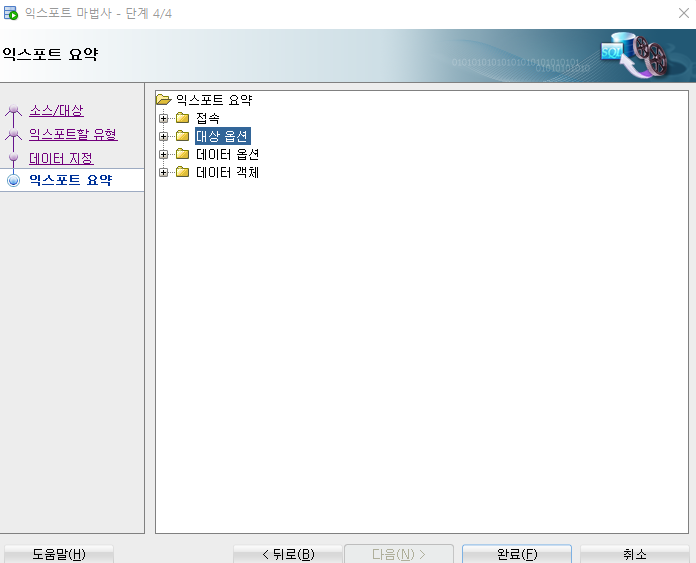

5. 완료를 클릭하고 파일이 만들어진 폴더에서 확인한다.
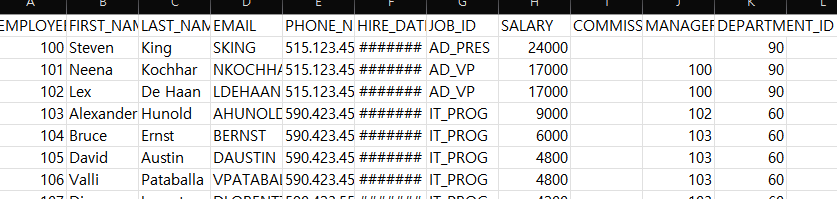

employees <- read.csv("c:/data/emp.csv",header = T) # /, \\ 둘다 가능
employees
str(employees)
names(employees)
colnames(employees)
head(employees)
tail(employees)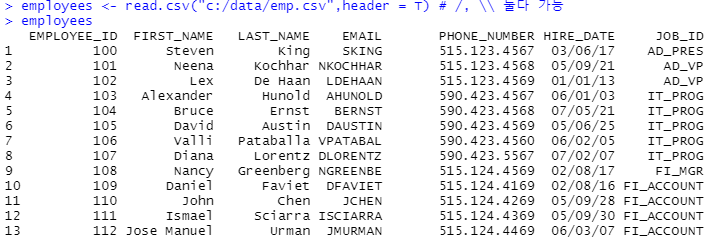

# SQL
SELECT * FROM employees WHERE employee_id = 100;
# R
employees$EMPLOYEE_ID == 100
employees[employees$EMPLOYEE_ID == 100,] # 조건에 해당하는 행만 추출
# SQL
SELECT last_name, salary FROM employees WHERE employee_id = 100;
# R
employees[employees$EMPLOYEE_ID == 100, c('LAST_NAME','SALARY')] # 조건에 해당하는 행만 추출
employees[which(employees$EMPLOYEE_ID == 100), c('LAST_NAME','SALARY')] # 조건에 해당하는 행만 추출
★ 데이터 프레임[행 추출조건, 열 추출]
#R
employees[employees$SALARY == 3000,c('LAST_NAME','SALARY')] # 급여가 3000인 사원의 last_name과 salary 열을 출력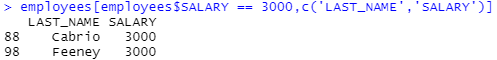
employees[employees$JOB_ID == 'AD_ASST' |employees$JOB_ID == 'MK_MAN', c('EMPLOYEE_ID','LAST_NAME','JOB_ID')]
employees[employees$JOB_ID %in% c('AD_ASST','MK_MAN'),c('EMPLOYEE_ID','LAST_NAME','JOB_ID')]
# JOB_ID가 AD_ASST,MK_MAN인 사원들의 employee_id, last_name, job_id를 출력
# department_id가 20,30번 사원들 중 급여가 10000원 이상인 사원들의 last_name,salary, department_id출력
employees[(employees$DEPARTMENT_ID ==20 |employees$DEPARTMENT_ID ==30) & employees$SALARY >= 10000, c('LAST_NAME','SALARY','DEPARTMENT_ID')]
employees[employees$DEPARTMENT_ID %in% c(20,30) & employees$SALARY >= 10000, c('LAST_NAME','SALARY','DEPARTMENT_ID')]
# &조건이 우선순위가 높아서 |에서 괄호로 묶음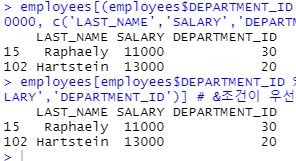
★ paste, paste0
- 변수에 값들을 하나로 묶는 함수
text1 <- '2022-01-10'
text2 <- '오늘하루도 행복하게 살자'
text3 <- '내년에도 늘 행복하자'
paste(text1,text2,text3)
paste(text1,text2,text3,sep=' ') # sep=' ' 값을 하나로 묶을 때 공백문자를 구분자로 입력해서 묶는다
paste(text1,text2,text3,sep=',')
paste(text1,text2,text3,sep='')
paste0(text1,text2,text3) # 공백문자를 없애고 묶음
★ na.omit
- NA가 있는 행을 삭제(데이터가 날아감, 필드 값에 NA가 있으면 NA에 해당하는 그 데이터의 행 싹 다 삭제) --주의해서 사용
'R' 카테고리의 다른 글
| R merge (0) | 2022.01.17 |
|---|---|
| R 함수(function) (0) | 2022.01.16 |
| R 조건제어문, 반복문 (0) | 2022.01.13 |
| R 중복제거, 정렬, 그룹함수 (0) | 2022.01.12 |
| R 문자함수, 숫자함수, 날짜함수 (1) | 2022.01.11 |