더보기
▣ 주요 키워드 ▣
- 중복제거
- unique
- 정렬
- sort, rev, order, doBy
- 그룹함수
- aggregate, apply, lapply, sapply, mapply, tapply
★ 중복제거
unique
unique(employees$JOB_ID) # job_id에서 중복되는 값을 제거하고 추출
na.omit(unique(employees$DEPARTMENT_ID)) # job_id에서 중복되는 값을 제거하고 na값도 제거하고 추출
as.integer(na.omit(unique(employees$DEPARTMENT_ID)))

★ 정렬
▶ sort
x <- c(6,9,2,3,5,4,7,1,8)
sort(x) #기본값은 오름차순
sort(x,decreasing = F) # 오름차순
sort(x,decreasing = T) # 내림차순
x <- c(6,9,2,3,NA,5,4,7,NA,1,NA,8)
sort(x) # 오름차순, NA출력 안 한다.
sort(x,decreasing = F, na.last = NA) # 기본값, 오름차순, NA출력X
sort(x,decreasing = F, na.last = T) # 마지막에 NA 출력
sort(x,decreasing = F, na.last = F) # 앞에 NA 출력
sort(x,decreasing = T, na.last = T) # 마지막에 NA 출력, 내림차순
sort(x,decreasing = T, na.last = F) # 앞에 NA 출력, 내림차순
▶ rev
- 역순 출력
x <- c(6,9,2,3,5,4,7,1,8,NA)
rev(x)
x[length(x):1]
rev(na.omit(x))
▶ order
- 정렬의 인덱스 번호를 반환하는 함수
x <- c(60,90,20,30,50,40,70,10,80)
sort(x)
order(x)
x[order(x)]
sort(x,decreasing = T)
order(x,decreasing = T)
x <- c(60,90,20,30,50,40,NA,70,NA,10,80)
sort(x,decreasing = T)
x[order(x,decreasing = T)]
order(x,decreasing = T, na.last = T) #기본값
order(x,decreasing = T, na.last = F)
▶ doBy
- 데이터프레임에서 정렬
install.packages("doBy") # 패키지를 다운받아서 사용할 수 있다.
library(doBy)
#sql
select last_name, salary
from employees
order by salary desc;
orderBy(~SALARY,employees[,c('LAST_NAME','SALARY')]) # ~포뮬러(formula)형식
orderBy(~DEPARTMENT_ID,employees[,c('LAST_NAME','SALARY','DEPARTMENT_ID')]) # 오름차순
orderBy(~-DEPARTMENT_ID,employees[,c('LAST_NAME','SALARY','DEPARTMENT_ID')]) # 내림차순
orderBy(~-SALARY,employees[,c('LAST_NAME','SALARY','DEPARTMENT_ID')]) # 내림차순
#sql
select last_name, salary
from employees
order by department_id,salary;
#R
orderBy(~DEPARTMENT_ID+SALARY,employees[,c('LAST_NAME','SALARY','DEPARTMENT_ID')]) # 여러개를 정렬할 때 '+'부호 사용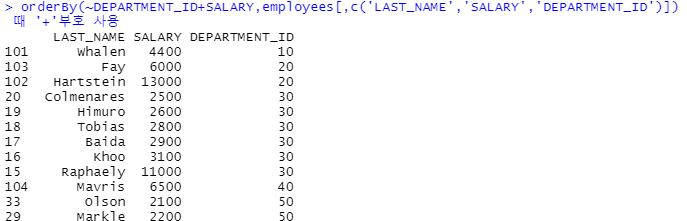
#sql
select last_name, salary
from employees
order by department_id,salary desc;
orderBy(~DEPARTMENT_ID-SALARY,employees[,c('LAST_NAME','SALARY','DEPARTMENT_ID')])
#department_id는 오름차순 salary는 내림차순으로 정렬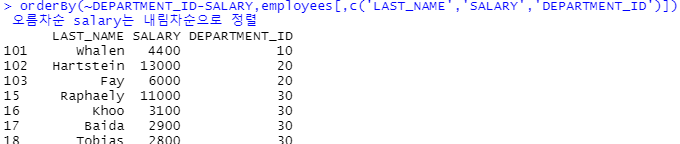
#sql
select last_name, salary
from employees
order by department_id desc,salary desc;
orderBy(~-DEPARTMENT_ID-SALARY,employees[,c('LAST_NAME','SALARY','DEPARTMENT_ID')])
#department_id는 내림차순 salary는 내림차순으로 정렬
#job_id가 ST_CLERK가 아닌 사원들의 last_name, salary, job_id를 출력.단 급여가 높은 사원부터 출력
X <- employees[employees$JOB_ID != 'ST_CLERK',c('LAST_NAME','SALARY','JOB_ID')]
x[order(x$SALARY, decreasing = T),]
orderBy(~-SALARY,x)
#사원 last_name, salary, commission_pct를 출력. 단commission_pct를 기준으로 오름차순정렬
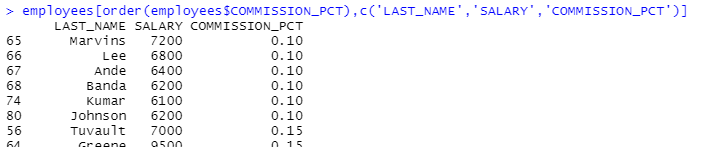
employees[order(employees$COMMISSION_PCT),c('LAST_NAME','SALARY','COMMISSION_PCT')]
orderBy(~COMMISSION_PCT, employees[,c('LAST_NAME','SALARY','COMMISSION_PCT')])
#commission_pct를 받고 있는 사원들의 last_name, salary, commission_pct를 출력. 단 commission_pct를 기준으로 오름차순정렬하세요.(na가 아닌)
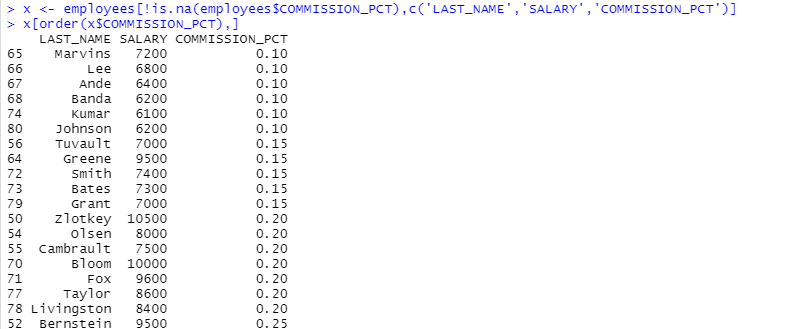
x <- employees[!is.na(employees$COMMISSION_PCT),c('LAST_NAME','SALARY','COMMISSION_PCT')]
x[order(x$COMMISSION_PCT),]
orderBy(~COMMISSION_PCT,x)


★ 그룹함수
x <- c(70,80,90,100)
sum(x) #합
mean(x) #평균
var(x) #분산
sd(x) # 표준편차
max(x) # 최대값
min(x) # 최소값
length(x) # 갯수 , 데이터프레임에서는 컬럼의 수
NROW(x) #행의 수
nrow(x) #벡터에서는 수행 x 데이터프레임에서 행의 수
x <- c(70,80,90,100,NA) #NA값이 있으면 계산 X
sum(x)
mean(x)
sum(na.omit(x))
sum(x,na.rm=T) # na.rm=T NA제거, NA.RM=F 기본값
mean(na.omit(x))
mean(x,na.rm=T)
var(x,na.rm=T)
sd(x,na.rm=T)
max(x,na.rm=T)
min(x,na.rm=T)
length(x)
NROW(x)
length(na.omit(x))
NROW(na.omit(x))
▶ aggregate
- 데이터를 분할하고 각 그룹으로 묶은 후 그룹 함수를 적용하는 함수
aggregate(SALARY ~ DEPARTMENT_ID, employees,sum)
# 데이터를 분할하고 DEPARTMENT_ID별로 그룹을 지어 그룹별 SALARY의 SUM을 구하기(합)
aggregate(SALARY ~ JOB_ID, employees, mean)
# 데이터를 분할하고 JOB_ID별로 그룹을 지어 그룹별 SALARY의 MEAN을 구하기(평균)
aggregate(EMPLOYEE_ID ~ JOB_ID, employees,NROW)
#JOB_ID별 인원수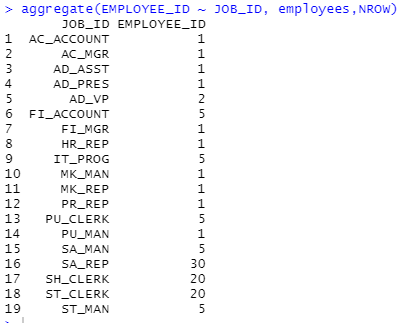
x <- aggregate(SALARY ~ DEPARTMENT_ID, employees, mean)
x[x$SALARY >= 8000,]
#DEPARTMENT_ID별로 평균급여를 구하고 그 급여가 8000이상인 정보 출력
x <- aggregate(SALARY ~ lubridate::year(HIRE_DATE), employees, sum)
#년도별 총액
class(x)
names(x) <- c('년도','총액') # 컬럼 이름 바꾸기
x
x <- aggregate(SALARY ~ lubridate::wday(HIRE_DATE,week_start = 1, label = T),employees,sum)
#요일별 총액
class(x)
names(x) <- c('요일','총액') # 컬럼 이름 바꾸기
x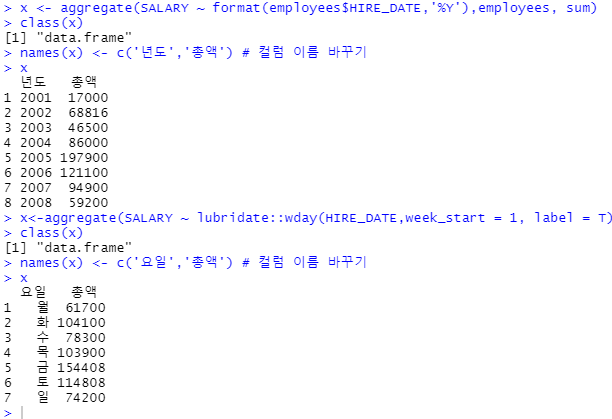
df <- data.frame(id = 100:104,
weight = c(60,90,74,95,65),
size = c('small','large','medium','large','small'))
df
str(df) # size를 chr에서 factor로 바꾸고 싶다
df$size <- factor(df$size, levels=c('small','medium','large'))
df
str(df)
df$size <- factor(df$size, levels=c('small','medium','large'), labels=c('작다','중간','크다'))
df
str(df)
▶ apply
- 함수를 반복수행
- 행렬, 배열, 데이터 프레임에 함수를 적용한 결과 벡터, 리스트, 배열 형태로 리턴하는 함수
m <- matrix(1:4, ncol=2)
m
sum(m[1,]) # 1행의 합
sum(m[2,]) # 2행의 합
sum(m[,1]) # 1열의 합
sum(m[,2]) # 2열의 합
apply(m,MARGIN = 1, sum) # MARGIN = 1 행 방향
apply(m,MARGIN = 2, sum) # MARGIN = 2 열 방향
● NA값이 중간에 섞여 있을 때 행의 합, 열의 합
df <- data.frame(name = c('king','smith','scott'),
sql = c(90,NA,70),
r = c(80,70,NA))
df
sum(df$sql,na.rm=T)
sum(df$r,na.rm=T)
apply(df[,c('sql','r')],MARGIN = 2, sum, na.rm=T) # 열의 합, na.rm=T NA제외
apply(df[,c('sql','r')],MARGIN = 1, sum, na.rm=T) # 행의 합
rowSums(df[,c('sql','r')]) # NA값이 있는 행은 NA가 출력
rowSums(df[,c('sql','r')],na.rm=T) # 행의 합, na.rm=T NA제외
colSums(df[,c('sql','r')])# NA값이 있는 열은 NA가 출력
colSums(df[,c('sql','r')],na.rm=T) # 열열의 합, na.rm=T NA제외
▶ lapply
- 벡터, 리스트, 데이터프레임에 함수를 적용하고 그 결과를 리스트로 반환하는 함수
x <- list(a=1:3,b=4:10,c=11:21)
x
length(x) # 방이 몇개인지
length(x$a) #방에 값이 몇개인지
length(x$b)
length(x$c)
lapply(x,length) #각 방들의 값의 개수
sum(x) #오류
sum(x$a) # x리스트의 a방에 값들을 모두 더한 값 출력
sum(x$b)
sum(x$c)
lapply(x,sum) #각각의 방들에 대한 합계를 구하기
lapply(x,mean) #각각의 방들에 대한 평균를 구하기
lapply(x,var) #각각의 방들에 대한 분산를 구하기
lapply(x,sd) #각각의 방들에 대한 표준편차를 구하기
lapply(x,max) #각각의 방들에 대한 최대값을 구하기
lapply(x,min) #각각의 방들에 대한 최소값을 구하기

df <- data.frame(name = c('king','smith','scott'),
sql = c(90,80,70),
r = c(80,70,60))
df
apply(df[,c(2,3)],MARGIN=2,sum) # 열의 합
apply(df[,c(2,3)],2,sum) # 열의 합
colSums(df[,c(2,3)]) # 열의 합
lapply(df[,c('sql','r')],sum) # 리스트 형식으로 출력
lapply(df[,c(2,3)],sum) # 리스트 형식으로 출력
df <- data.frame(name = c('king','smith','scott'),
sql = c(90,NA,70),
r = c(80,70,NA))
df
apply(df[,c(2,3)],MARGIN=2,sum,na.rm=T) # 열의 합
apply(df[,c(2,3)],2,sum,na.rm=T) # 열의 합
colSums(df[,c(2,3)]) # 열의 합
lapply(df[,c(2,3)],sum,na.rm=T) # 리스트 형식으로 열의 합 출력

▶ sapply
- 벡터, 리스트, 데이터프레임에 함수를 적용하고 그 결과를 벡터로 반환하는 함수
x <- list(a=1:3,b=4:10,c=11:21)
x
lapply(x,length) # x(리스트)변수의 a,b,c방의 값의 각각 개수를 리스트형으로 출력
unlist(lapply(x,length)) # 리스트형을 벡터형으로 변경
sapply(x,length) # 바로 벡터형으로 출력
df <- data.frame(name = c('king','smith','scott'),
sql = c(90,NA,70),
r = c(80,70,NA))
df
sapply(df[,c(2,3)],sum,na.rm=T) #벡터형으로 sql, r컬럼의 값들의 합을 출력▶ mapply
- 다수의 인수값을 입력하여 함수를 반복 수행해서 리스트 형으로 리턴하는 함수
rep(1,5) # 1을 5번 출력
rep(2,4) # 2를 4번 출력
rep(3,3) # 3을 3번 출력
rep(4,2) # 4를 2번 출력
rep(5,1) # 5를 1번 출력
mapply(rep,1:5,5:1) # 위의 5줄의 코드를 리스트형으로 출력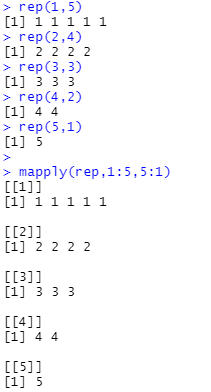
▶ tapply
- 벡터, 데이터프레임에 저장된 데이터를 주어진 기준에 따라 그룹을 묶은 뒤 그룹 함수를 적용하고 그 결과를 array(가로 형식) 형식으로 리턴하는 함수
aggregate(SALARY ~ DEPARTMENT_ID, employees, sum) # 세로형식의 그룹함수 aggregate
tapply(employees$SALARY, employees$DEPARTMENT_ID, sum) # 가로 형식의 그룹함수 tapply
class(tapply(employees$SALARY, employees$DEPARTMENT_ID, sum)) # array형식(vector x)
1.aggregate
aggregate(SALARY ~ DEPARTMENT_ID+JOB_ID, employees, sum)
# 두개(DEPARTMENT_ID,JOB_ID) 이상 그룹핑할 때 세로
orderBy(~DEPARTMENT_ID, aggregate(SALARY ~ DEPARTMENT_ID+JOB_ID, employees, sum))
# DEPARTMENT_ID로 정렬
2.tapply
tapply(employees$SALARY, list(employees$DEPARTMENT_ID,employees$JOB_ID), sum)
#행은 DEPARTMENT_ID 열은 JOB_ID로 출력
#tapply함수에서 두개 이상의 그룹을할 때는 list형식으로 작성하고 첫 번째 작성한 부분이 행,
두번째작성한 부분이 열로 출력된다.
tapply(employees$SALARY, list(employees$JOB_ID,employees$DEPARTMENT_ID), sum) # 반대
#행은 JOB_ID, 열은 DEPARTMENT_ID로 출력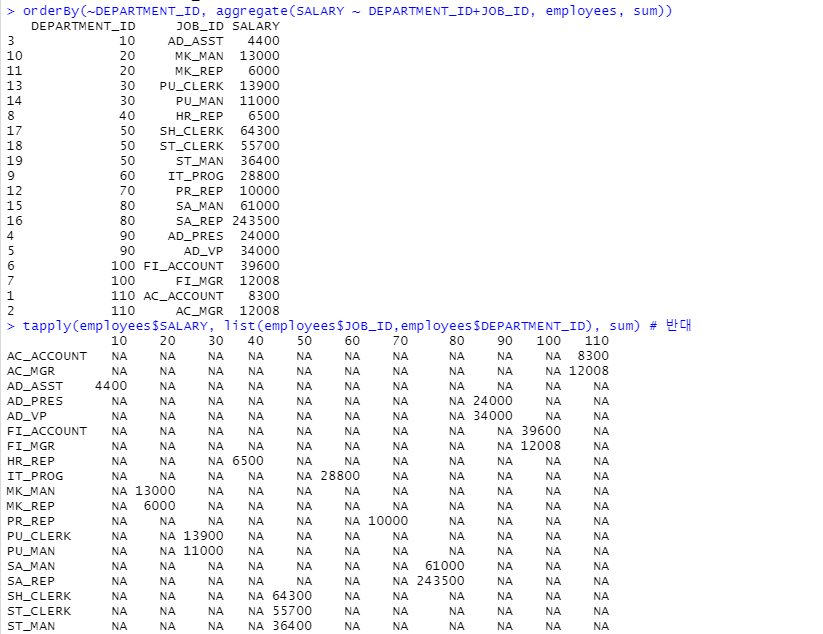
tapply(employees$SALARY, list(employees$JOB_ID,employees$DEPARTMENT_ID), sum, default=0)
# default=0은 NA값을 다른 값으로 설정
'R' 카테고리의 다른 글
| R merge (0) | 2022.01.17 |
|---|---|
| R 함수(function) (0) | 2022.01.16 |
| R 조건제어문, 반복문 (0) | 2022.01.13 |
| R 문자함수, 숫자함수, 날짜함수 (1) | 2022.01.11 |
| R공부 matrix, array, factor, data frame (0) | 2022.01.11 |