▣ 주요 키워드 ▣
- 함수(function)
- 매개변수
- 가변인수
- 전역변수
- 2중함수
벡터, 데이터 프레임, rbind 관계
a <- c(1:5) #벡터
b <- c(6:10)
x <- c(a,b)
x
for(i in 100:105){
x <- c(x,i) #x라는 벡터에 i값을 하나씩 반복문을 통해 추가
}
x
new_matrix <- rbind(a,b)
class(new_matrix) #matrix, array 형식
df <- data.frame(x = c(1:5), # 데이터프레임 형식으로 만들기
y = c(6:10),
z = c(11:15))
data <- c(16:19)
data
df_new <- rbind(df,data) # data, df 행 길이가 다를 때 행길이만큼만 들어오고 나머지는 안 들어옴
df_new
df1 <- data.frame(x = c(11,12,13),
y = c(15,14,16),
z = c(18,17,19))
rbind(df,df1) # 데이터프레임을 행 합칠때는 열의 수와 열 이름이 동일해야한다.
변수에 벡터 선언
new = c() #벡터 선언
new <- c(new,1) #new변수에 벡터new,1 값을 초기화
new
new = NULL # NULL값으로 new변수 선언
new <- c(new,1) #new변수에 벡터new,1 값을 초기화
new
값이 없는 데이터프레임에 행 추가
df <- data.frame() # df변수에 data.frame선언한 것을 초기화
df
new_df <- rbind(df,c(1:9)) #df변수(데이터프레임)에 1:9값을 추가하고 new_df변수에 초기화
new_df <- rbind(new_df,c(10:19)) #new_df변수(데이터프레임)에 원래있던 new_df값과 10:19값을 행추가하고 다시new_df변수에 초기화
new_df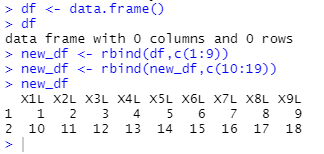
각 칼럼 별 구구단
● 행단위로 추가, 빈 데이터프레임 선언
df <- data.frame()
for(i in 1:9){
temp <- NULL
for(j in 2:9){
temp <- c(temp,paste(j,'*',i,'=',j*i))
}
df <- rbind(df,temp) #행단위로 할 때는 rbind 사용가능
}
df
names(df)
n <- NULL
for(i in 2:9){
n <- c(n,paste0(i,'단'))
}
names(df) <- n
df
df$'2단' #컬럼이름에서 숫자가 앞에 온다면 작은따옴표를 꼭 사용
● 열단위로 추가, 데이터프레임 틀 미리 만들기
matrix(NA, nrow=9,ncol=8)
df <- data.frame(matrix(NA, nrow=9,ncol=8)) # 뼈대를 만들어 놓음
df
for(i in 2:9){
temp <- NULL
for(j in 1:9){
temp <- c(temp, paste(i, '*',j,'=',i*j))
}
df[,i-1] <- temp # cbind는 안됨, 열단위로는 안되고 rbind(행단위)만 됨, 열별로 할 때는 뼈대를 만들어 놓고 열별로 다시 넣어주는 작업을 해야함
}
df▶다음과 같이 출력하기(salary값을 기준으로 1000당 '*' 1개씩 출력)
name sal star
King 24000 ************************
Kochhar 17000 *****************
De Haan 17000 *****************
Hunold 9000 *********
Ernst 6000 ******
Austin 4800 ****
Pataballa 4800 ****
......
num <- trunc(employees$SALARY/1000) #num변수에 salary값을 1000으로 나눈 값을 나머지는 버린 값
star <- NULL #star변수 선언(후에 컬럼이 될 변수)
for(i in num){ # for문 시작(num의 변수에 있는 값들이 하나씩 들어감)
v <- NULL # v변수 선언
for(i in 1:i){ #2중 for문 1부터 i(num값)까지 반복
v <- paste0(v,'*') #v변수에 '*'값을 중복하고 전의 v값과 붙여서 v변수에 초기화( i번 반복)
}
star <- c(star,v) # star변수에 1부터 i번 반복해서 추가된 벡터star,v값을 초기화(한 행씩 추가됨)
}
star
df <- data.frame(name=employees$LAST_NAME,
sal=employees$SALARY,
star=star)
df[nchar(df$star) != num,] #별의 개수가 맞는지 확인

②데이터프레임을 먼저만들기(na값이 하나 있을 때)
df <- data.frame(name=employees$LAST_NAME,
sal=employees$SALARY,
star=NA) # 컬럼을 선언할 때 NULL은 X, NA만, NULL은 변수선언할 때
df[107,'sal'] <- NA #107번의 salary값을 na로 초기화
df
idx <- 1 # idx변수는 star컬럼에서 각 행의 위치를 갖는 변수
for(i in df$sal){ #df$sal에 있는 값들을 하나씩 반복해서 수행
if(is.na(i)){ #i(df$sal)값이 na이면 next함수를 사용해서 다음 i값으로 넘어가는 로직
next
}else{ # i값이 na가 아니면 수행할 로직
v <- NULL # '*'이 들어갈 변수를 선언
for(j in 1:trunc(i/1000)){ # salarty/1000만큼의 '*'의 개수를 v변수에 초기화
v <- paste0(v,'*')
}
df[idx,'star'] <- v # v변수의 값을 df(데이터프레임)의 star컬럼의 idx번째에 초기화
idx <- idx + 1 # idx변수를 1씩 증가시키면서 star컬럼의 다음 행으로 넘어가는 작업을 위해서
}
}
★ 함수(function)
- 반복되어 사용하는 기능을 정의하는 프로그램
- 기능의 프로그램
예)
함수 이름 <- function(){
함수 내에서 수행해야 할 코드
return(반환 값) # 선택
}
● format(Sys.Date(),'%Y%m%d')를 리턴하는 date1이라는 함수 만들기
#----------
Sys.Date()
format(Sys.Date(),'%Y%m%d')
#----------
date1 <- function(){ #date1 변수에 함수를 넣기
return(format(Sys.Date(),'%Y%m%d')) #date1 함수를 호출하면 리턴해주는 값
}
date1() #함수 호출
▶ 매개변수(parameter variable)
- 형식 매개변수(formal parameter variable) : arg1, arg2, 입력 변수, 매개변수의 이름은 편한 것으로 아무거나 가능
- 실제 매개변수(actual parameter variable) : 호출하는 함수에서 값을 넣어 매개변수로 들어가는 값
hap <- function(arg1,arg2){ #매개변수 arg1, arg2
res <- arg1 + arg2
return(res) #res변수 리턴
}
hap(100,200) #100 -> arg1, 200 -> arg2 #실제매개변수 100,200가 형식매개변수 arg1, arg2로 순서대로 들어감

⊙ 1부터 입력 숫자까지 누적합을 구하는 함수
hap <- function(x){
y <- 0 # 누적합이 들어갈 변수 선언
for(i in 1:x){ #누적합 구하는 구문
y <- y + i
}
return(y)
}
hap(3) # hap함수 호출 매개변수로 3이 들어가서 1부터 3까지의 합을 구함
⊙ 1부터 입력숫자까지 홀수의 합
odd <- function(arg1){ # i값을 2로 나누었을 때 나머지 값이 1이면(홀수) y변수에 i값 더해서 y변수 리턴
y <- 0 # 누적합 구하는 변수
for(i in 1:arg1){
if(i%%2==1){
y <- y + i
}
}
return(y)
}
odd(10)
odd <- function(arg1){ # i값을 2로 나누었을 때 나머지 값이 0이면(짝수) 다음 값으로 넘어가기, 0이 아니면 temp변수에 i값 더해서 temp변수 리턴
temp <- 0
for(i in 1:arg1){
if(i%%2==0){
next
}
temp <- temp + i
}
return(temp)
}
odd(10)
⊙ 약수를 리턴하는 함수 만들기
※약수 : 어떤 수를 나누어 떨어지게 하는 자연수
예) 12의 약수 1,2,3,4,6,12
수행 과정
12 %% 1 ==0
12 %% 2 ==0
12 %% 3 ==0
12 %% 4 ==0
12 %% 5 ==0
12 %% 6 ==0
12 %% 7 ==0
12 %% 8 ==0
12 %% 9 ==0
12 %% 10 ==0
12 %% 11 ==0
12 %% 12 ==0
divisor <- function(arg1){
y <- NULL
for(i in 1:arg1){
if(arg1%%i==0){
y <- c(y, i)
}
}
return(y)
}
divisor(12)
# 약수는 자기 자신을 제외하고 1/2까지만 약수가 된다.
divisor <- function(arg1){
temp <- NULL
for(i in 1:(arg1/2)){
if(arg1%%i==0){
temp <- c(temp,i)
}
}
return(c(temp,arg1))
}
divisor(10)

▶ 가변 인수 : (...)
- 매개변수 안에 여러 경우의 값을 받을 인수값
f <- function(arg){
for(i in arg){
print(i)
}
}
f(c(1,2,3,4,5))
f(1,2,3,4,5) # 오류
f(1:5)
f <- function(...){
for(i in list(...)){
print(i)
}
}
f <- function(...){
for(i in c(...)){
print(i)
}
}
f(c(1,2,3,4,5))
f(1,2,3,4,5)
f(1:5)

⊙ 합을 구하는 함수
hap <- function(...){ #가변인수
sum_h <- 0
for(i in c(...)){ # 가변인수를 벡터형으로 i값에 하나씩 반복해서 sum_h값에 누적 합
sum_h <- sum_h + i
}
return(sum_h) # sum_h 리턴
}
hap(c(1,2,3,4,5))
hap(1,2,3,4,5)
hap(1:10)
hap <- function(...){
v_sum <- 0
for(i in list(...)){ #list형식으로
v_sum <- v_sum + i
}
return(v_sum)
}
hap(c(1,2,3,4,5))
hap(1,2,3,4,5)
hap(1:10)
⊙ 평균을 구하는 avg함수 생성
#--------------- 기존 base함수사용
y <- c(1,2,3,NA,4,5,NA)
mean(y)
mean(y,na.rm=T)
avg(y)
#---------------
1.
avg <- function(...){
temp <- 0
num <- 0
for(i in c(...)){
if(is.na(i)){
next
}
temp <- temp + i
num <- num + 1
}
return(temp/num)
}
avg(y)
2.
avg <- function(...){
x <- na.omit(c(...)) # 가변인수값에서 na값을 빼고 x변수에 초기화
v_sum <- 0
v_cn <- 0
for(i in x) {
v_sum <- v_sum +i
v_cn <- v_cn +1
}
return(v_sum/v_cn)
}
avg(y)
⊙ 짝수, 홀수를 출력하는 함수 생성
odd_even <- function(...){
odd1 <- NULL
for(i in c(...)){
if(i%%2==0){
odd1 <- c(odd1,'짝수')
}else{
odd1 <- c(odd1,'홀수')
}
}
return(odd1)
}
odd_even(c(1,2,3,4,5))
odd_even(1:5)
odd_even(1,2,3,4,5)
#ifelse버젼
odd_even <- function(...){
ifelse(c(...)%%2==0,"짝수","홀수")
}
lst <-list(1,2,3,4,5)
odd_even(lst) # 리스트형식
odd_even(lst[[1]]) # 첫 번째 리스트
odd_even(lst[[2]]) # 두 번째 리스트
odd_even(unlist(lst)) # 리스트를 벡터형으로
lapply(lst,odd_even) #리스트로
sapply(lst,odd_even) #벡터로
lapply(lst,function(arg){ifelse(arg%%2==0, "짝수","홀수")}) #한줄짜리 함수를 lapply함수 넣기
sapply(lst,function(arg){ifelse(arg%%2==0, "짝수","홀수")})
▶ 전역 변수(global variable)
- R프로그램이 수행되는 동안에, 메모리에서 지우기 전까지 어디서든 사용할 수 있는 변수
x <- 1
y <- 2
z <- 3
ls()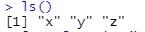
f <- function(){
y <-20 # 지역변수(private variable, local variable) : 함수내에서만 사용되는 변수
print(x)
print(y)
print(z)
}
f()
y # 위에 y값이 아닌 이 전에 초기화시킨 전역변수 y
ls()
rm(list=ls()) # 현재까지 사용한 변수들 다 삭제
ls()
f <- function(){
x <<- 10 # '<<-'전역변수
y <- 20 # '<-' 지역변수
z = 30 # '=' 지역변수
print(x)
print(y)
print(z)
}
ls()
f() # 함수를 호출했을 때 x(전역변수)값이 초기화 됨
ls()
x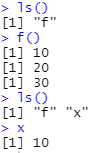
ls()
rm(list=ls())
ls()
x <- 100
x
ls()
f <- function(){
x <<- 1 # '<<-'전역변수
y <- 20 # '<-' 지역변수
z = 30 # '=' 지역변수
print(x)
print(y)
print(z)
}
ls()
f()
ls()
x #함수 밖에서 초기화한 전역변수 x는 함수에서 전역변수로 다시 초기화했을 때 그 값으로 변경이 됨
▶ 함수(function) 안에 다른 함수(function)
f <- function(arg1,arg2){
print(arg1)
f1 <- function(arg3){
arg3 <- arg1 + arg3 # arg3 <- 10 + 20
print(arg3)
}
f1(arg2) #arg2(20) -> f1.arg3(20), f함수에서 f1함수를 호출
print(arg1)
print(arg2)
#print(arg3) 실행x f안에 f1함수에 있는 변수를 사용할 수 없음
}
f(10,20) # 10 -> arg1, 20 -> arg2
- private variable : 함수가 중첩된 함수일 경우 메인 함수의 arg1, arg2는 함수 내에서 어디서든지 사용 가능
- local variable : 함수가 중첩된 함수 일 경우 중첩 함수에서 선언된 arg3변수는 중첩함수 내에서만 사용할 수 있다
f <- function(arg1,arg2){
x1 <- arg1 #x1변수는 private variable 즉 f함수내에서 어디서든지 사용할 수 있다.
x2 <- arg2 #x1변수는 private variable 즉 f함수내에서 어디서든지 사용할 수 있다.
f1 <- function(arg3){
x3 <- x1+x2 + arg3 #x3변수는 local variable, 즉 x3변수는 f1함수 내에서만 사용해야 한다.
print(x3)
}
f1(x2) #arg2(20) -> f1.arg3(20)
print(x1)
print(x2)
print(x3) # 오류발생 : local variable는 자신의 함수 내에서만 사용해야 하기 때문에 오류 발생
}
f(10,20)
⊙ avg함수 안에 hap함수를 중첩해서 avg함수 생성
avg <- function(...){
x <- na.omit(c...))
hap <- function(...){ #hap함수에서 누적합을 구하는 함수구현
y <- 0
for(i in x){
y <- y + i
}
return(y)
}
return(hap(x)/length(x)) #avg함수에서 hap(x)함수 호출 x벡터의 길이만큼 나눠줌(na는 na.omit에서 빼서 길이에 더해지지않음)
}
avg(1,2,3,NA,4,5,NA)
'R' 카테고리의 다른 글
| R subset,ddply 함수 (0) | 2022.01.19 |
|---|---|
| R merge (0) | 2022.01.17 |
| R 조건제어문, 반복문 (0) | 2022.01.13 |
| R 중복제거, 정렬, 그룹함수 (0) | 2022.01.12 |
| R 문자함수, 숫자함수, 날짜함수 (1) | 2022.01.11 |