▣오늘의 주요 키워드▣
- INLINE VIEW
- PIVOT, UNPIVOT
[문제66] Executive 부서이름의 소속된 모든 사원에 대한 department_id, last_name, job_id 출력하세요.
1)서브쿼리
select department_id, last_name, job_id
from employees
where department_id = (select department_id
from departments
where department_name ='Executive');
2)join
select e.department_id, last_name, job_id
from employees e, departments d
where e.department_id = d.department_id
and d.department_name = 'Executive';
/* =
select e.department_id, last_name, job_id
from employees e join departments d
on e.department_id = d.department_id
and d.department_name = 'Executive';
*/
- 66번 문제는 서브 쿼리 or 조인을 사용하여 해결한다.
[문제67] 전체 평균 급여보다 많은 급여를 받고 last_name에 'z'가 포함된 사원과
같은 부서에서 근무하는 모든 사원의 employee_id, last_name, salary 출력하세요
1)보통 답
SELECT employee_id, last_name, salary
FROM employees
WHERE department_id in (select department_id
from employees
where last_name like '%z%') --instr(last_name, 'z',1,1) > 0로 대체가능
and salary > (select avg(salary)
from employees);
2)exists연산자 활용
SELECT employee_id, last_name, salary
FROM employees o
where exists (select 'x'
from employees
where department_id =o.department_id
and last_name like '%z%')
and salary > (select avg(salary)
from employees);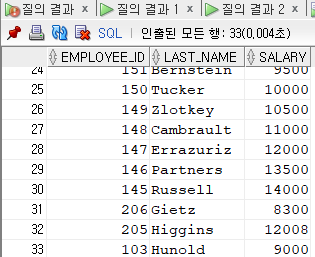
-두 가지 풀이법 중에 위에 1번 풀이법은 in연산자를 사용해서 중복되는 값들을 일일이 계속 비교해야 하는 단점이 있지만 2번 풀이법에서 그 해결책인 exists연산자를 활용하여 in의 단점을 보완한다.
다시 살펴보기!!
자신의 부서 평균급여 보다 더 많은 급여를 받는 사원?
SELECT *
FROM employees
WHERE salary > 자신의 부서 평균급여;
SELECT *
FROM employees o
WHERE salary > (SELECT avg(salary)
FROM employees
WHERE department_id = o.department_id);
문제점은?
후보행 값이 동일한 값으로 다시 입력이 될 때 평균을 다시 계산해야 한다는 문제점(i.o, cpu를 또 써야하는 문제)
해결책?
부서별 평균 급여가 있는 테이블만 있으면 좋을텐데
dept_avg테이블이 있다 가정
select department_id, avg(salary) avg_sal
from employees
group by department_id;
select e.*
from employees e, dept_avg d
where e.department_id = d.department_id
and e.salary > d.avg_sal;
★INLINE VIEW
- 가상테이블
- FROM절에 subquery를 INLINE VIEW라고 함
위의 내용을 INLINE VIEW로 표현
SELECT *
FROM (select department_id dept_id, avg(salary) avg_sal --그룹함수는 별칭을 꼭 쓰자( 그냥 그룹함수는 where절에서 못 쓰기때문에)
from employees
group by department_id) dept_avg, employees e
WHERE e.department_id = dept_avg.dept_id
and e.salary > dept_avg.avg_sal;
[문제68] 사원수가 가장 많은 부서이름, 도시, 인원수를 출력해주세요.
1)부서이름, 도시 조인
select d.department_name, l.city
from departments d, locations l, employees e
where e.department_id = d.department_id
and d.location_id = l.location_id
2)부서이름별로 인원수 구하기
select d.department_name, l.city , count(*)
from departments d, locations l, employees e
where e.department_id = d.department_id
and d.location_id = l.location_id
group by d.department_name, l.city;
3)가장 많은 인원이 있는 부서이름, 도시, 인원수 출력
select d.department_name, l.city , count(*)
from departments d, locations l, employees e
where e.department_id = d.department_id
and d.location_id = l.location_id
group by d.department_name, l.city
having count(*) = (select max(count(*))
from employees
group by department_id);
>INLINE VIEW 관점에서 풀기(위의 코드는 비효율적인 동작이 있기에 더 효율적으로 바꾼 코드)
1)한 건의 데이터로 만들기
select department_id, count(*) cnt
from employees
group by department_id
having count(*) = (select max(count(*))
from employees
group by department_id);
2)만든 데이터를 가상테이블로
select d.department_name, l.city, e.cnt
from (select department_id, count(*) cnt
from employees
group by department_id
having count(*) = (select max(count(*))
from employees
group by department_id)) e, departments d, locations l
where e.department_id = d.department_id
and d.location_id = l.location_id;
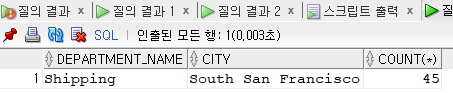
-어떻게 하면 더 효율적으로 문제를 풀 수 있을지 생각하라. 위의 문제에서는 INLINE VIEW라는 가상 테이블을 이용해서 비효율적인 동작을 완전 최소화할 수 있었다.
※INLINE VIEW를 사용해서 한 이유는?
-조인 작업하는 양을 줄이기 위해서 사용하려는 의도
[문제69] 입사가 가장 많은 요일에 입사한 사원들의 employee_id, last_name, 요일 출력해주세요.
1)출력할 것
SELECT employee_id, last_name, to_char(hire_date, 'dy')
FROM employees;
2)입사가 가장 많은 요일
SELECT to_char(hire_date,'dy'), count(*)
FROM employees
GROUP BY to_char(hire_date,'dy')
HAVING count(*) = (SELECT max(count(*))
FROM employees
GROUP BY to_char(hire_date, 'dy'));
3)최종
SELECT employee_id, last_name, to_char(hire_date, 'dy')
FROM employees e, (SELECT to_char(hire_date,'dy') day2, count(*)
FROM employees
GROUP BY to_char(hire_date,'dy')
HAVING count(*) = (SELECT max(count(*))
FROM employees
GROUP BY to_char(hire_date, 'dy'))) d
WHERE to_char(e.hire_date, 'dy') =d.day2;
-------------------------------------------------------------
강사님 답
desc employees
select employee_id, last_name, to_char(hire_date, 'day')
from employees
where to_char(hire_date, 'day') in (select to_char(hire_date, 'day')
from employees
group by to_char(hire_date, 'day')
having count(*) = (select max(count(*))
from employees
group by to_char(hire_date, 'day')));
큰 테이블을 세 번이나 반복하고 있으니 비효율적이다? 생각해보자
요일별로 나오는 것처럼 보이지만 정렬된 것은 아니다 나중에는 정렬을 해줘야할 때 따로 해줘야한다.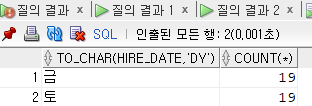
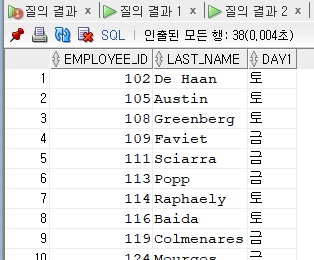
-내 답은 가상 테이블을 만들고 조인을 사용하였고 강사님은 조건문에서 in 연산자와 서브 쿼리만을 이용
★가로 정렬
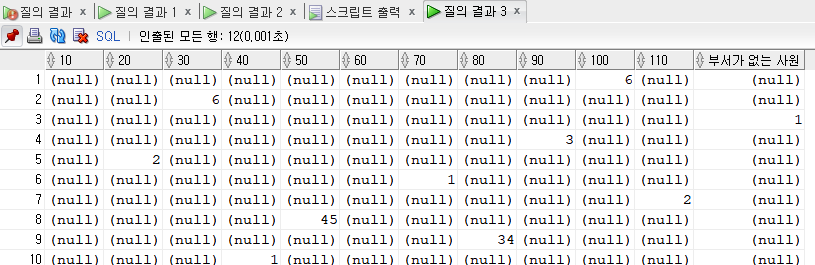
[문제70] 부서별로 인원수를 출력주세요.
10 20 30 40 50 60 70 80 90 100 110 부서가 없는 사원
---------- ---------- ---------- ---------- ---------- ---------- ---------- ---------- ---------- ---------- ---------- ----------------
1 2 6 1 45 5 1 34 3 6 2 1
1)세로
SELECT department_id, count(*)
FROM employees
group by department_id;
2)가로
SELECT
count(decode(department_id, 10,1)) "10",
count(decode(department_id, 20,1)) "20",
count(decode(department_id, 30,1)) "30",
count(decode(department_id, 40,1)) "40",
count(decode(department_id, 50,1)) "50",
count(decode(department_id, 60,1)) "60",
count(decode(department_id, 70,1)) "70",
count(decode(department_id, 80,1)) "80",
count(decode(department_id, 90,1)) "90",
count(decode(department_id, 100,1)) "100",
count(decode(department_id, 110,1)) "110",
count(decode(department_id, null,1)) "부서가 없는 사원"
FROM employees;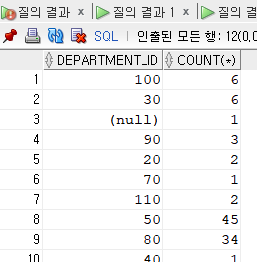

위의 식은 107 row decode 12번 반복한다.
decode 함수는 몇 번 수행되나요? 107 * 12 = 이렇게 많이 돌아가는 문제가 있음
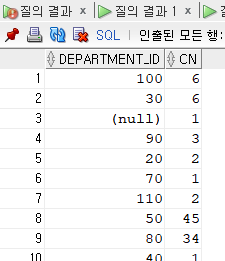
decode 함수는 12번 반복 수행할 수 있도록 개선을 해보세요.
select
max(decode(department_id, 10,cn)) "10",
max(decode(department_id, 20,cn)) "20",
max(decode(department_id, 30,cn)) "30",
max(decode(department_id, 40,cn))"40",
max(decode(department_id, 50,cn))"50",
max(decode(department_id, 60,cn))"60",
max(decode(department_id, 70,cn)) "70",
max(decode(department_id, 80,cn)) "80",
max(decode(department_id, 90,cn)) "90",
max(decode(department_id, 100,cn)) "100",
max(decode(department_id, 110,cn)) "110",
max(decode(department_id, null,cn)) "부서가 없는 사원"
from (select department_id, count(*) cn
from employees
group by department_id);-같은 결과가 나오는데 이 코드는 밑에 from절에 서브 쿼리인 가상 테이블을 이용해서 수행할 동작을 최소화(가상 테이블에서 이미 count와 그룹핑을 해놓고 select문에서는 끼워 맞추기만 하면 된다. 107* 12번 할 것을 12*12번으로 줄인 것이다. 그리고 max(그룹 함수 종류)를 앞에 붙이는 이유는 안 붙이게 되면 12 x 12의 형태처럼 나오기 때문이다.
★pivot 함수
-행(세로) 데이터를 열(가로)로 변경하는 함수
1)부서별 인원수
select *
from (select department_id
from employees)
pivot(count(*) for department_id in (10 "10번 부서",20,30,40,50,60,70,80,90,100,110,null as "부서가 없는 사원"));
2)부서별 총급여
select *
from (select department_id, salary
from employees)
pivot(sum(salary) for department_id in(10 "10번 부서",20,30,40,50,60,70,80,90,100,110,null as "부서가 없는 사원"));

-pivot는 세로 데이터를 가로로 정렬할 때 아주 유용한 함수이다. 전에 구했던 select문에서 decode무한 반복하는 귀찮고 불편한 작업을 편리하게 수행할 수 있는 함수이다. pivot(작업할 것 for 기준 칼럼 in(비교 칼럼)) 이런 식으로 작성된다. 그리고 중요한 것은 가상 테이블이 필수라는 점이다.
[문제71] 년도별 입사 인원수를 출력해주세요.
2001 2002 2003 2004 2005 2006 2007 2008
---------- ---------- ---------- ---------- ---------- ---------- ---------- ----------
1 7 6 10 29 24 19 11
1)세로
select to_char(hire_date, 'yyyy'), count(*)
from employees
group by to_char(hire_date,'yyyy');
2)가로
SELECT *
FROM (SELECT to_char(hire_date,'yyyy') year
FROM employees)
pivot (count(*) for year in ('2001','2002','2003','2004','2005','2006','2007','2008'));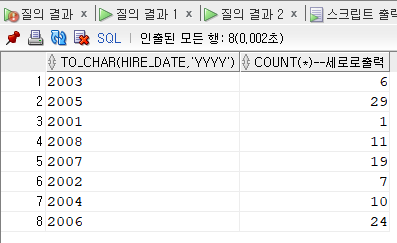

[문제 72] 요일별 입사 인원수를 가로 방향으로 출력해주세요.
select *
from (select to_char(hire_date,'day') day
from employees)
pivot (count(*) for day in ('월요일' "월요일", '화요일' "화요일", '수요일' "수요일", '목요일' "목요일", '금요일' "금요일", '토요일' "토요일", '일요일' "일요일"));
[문제 73] 요일별 급여의 총액을 가로 방향으로 출력해주세요.
select *
from (select to_char(hire_date, 'day') day, salary
from employees)
pivot (sum(salary) for day in ('월요일' "월요일", '화요일' "화요일", '수요일' "수요일", '목요일' "목요일", '금요일' "금요일", '토요일' "토요일", '일요일' "일요일"));

★unpivot 함수
- 열(가로)을 행(세로)으로 변경하는 함수
select *
from (select *
from (select to_char(hire_date, 'day') day, salary
from employees)
pivot (sum(salary) for day in ('월요일' "월요일", '화요일' "화요일", '수요일' "수요일", '목요일' "목요일", '금요일' "금요일", '토요일' "토요일", '일요일' "일요일")))
unpivot(급여총액 for 요일 in (월요일, 화요일, 수요일, 목요일, 금요일, 토요일, 일요일));-pivot 했던 코드를 가상 테이블에 넣고 unpivot을 하면 세로로 출력된다.
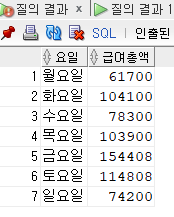
응용
select 요일 , to_char(급여총액, '999,999') 급여총액
from (select *
from (select to_char(hire_date, 'day') day, salary
from employees)
pivot (sum(salary) for day in ('월요일' "월요일", '화요일' "화요일", '수요일' "수요일", '목요일' "목요일", '금요일' "금요일", '토요일' "토요일", '일요일' "일요일")))
unpivot(급여총액 for 요일 in (월요일, 화요일, 수요일, 목요일, 금요일, 토요일, 일요일))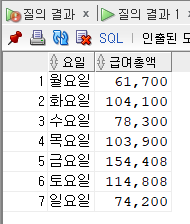
'SQL' 카테고리의 다른 글
| 12.29 오늘의 공부 (0) | 2021.12.29 |
|---|---|
| 12.28 오늘의 공부 (0) | 2021.12.28 |
| 12.24 오늘의 공부 (0) | 2021.12.24 |
| 12.23 오늘의 공부 (0) | 2021.12.23 |
| 12.22 오늘의 공부 (0) | 2021.12.22 |